

Document ranking is the process in information retrieval ranking where a system orders documents by relevance to a query, so the most useful results appear first. Document ranking in information retrieval defines how search systems evaluate a document collection using relevance signals, which include lexical relevance, semantic relevance, authority signals, user behavior signals, and technical signals. Document ranking evolved from early mathematical models (Wassily Leontief 1941) to Boolean retrieval, TF-IDF in the 1970s, BM25 in the 1990s, PageRank in 1998, and modern neural ranking systems (BERT, transformer models). What is document ranking in the SEO context refers to how search engine document ranking determines visibility, clicks, and traffic distribution across search results.
Document ranking works through a multi-stage pipeline where retrieval selects candidate documents and ranking reorders them using scoring models and system signals. Search engine document ranking processes queries by retrieving matching documents, scoring each document using models (TF-IDF, BM25, PageRank, neural ranking), and combining signals into a final ranking score. Google document ranking systems operate as a multi-system architecture where systems (BERT, RankBrain, neural matching, passage ranking) generate signals, and quality systems (Helpful Content, SpamBrain, Page Experience) constrain ranking outcomes. Document ranking applies in both classical information retrieval and modern search, where ranking documents shifts from keyword matching to semantic understanding and entity-based evaluation.
Document ranking SEO matters because ranking position controls visibility, traffic, and business outcomes, and optimization requires multi-signal analysis using specialized tools. Document ranking SEO drives over 53% of website traffic from organic search, and top positions capture the majority of clicks, which makes ranking performance critical for growth. Document ranking improves through methods (re-ranking, LLM optimization, Learning to Rank, entity-based indexing, RAG optimization, metadata structuring), which increase relevance, precision, and authority signals. Search Atlas (tool) provides the most complete workflow for document ranking optimization by combining rank tracking, content scoring, technical audits, and backlink analysis, while Google Search Console (tool) provides ground-truth query, impression, and position data. These tools enable continuous measurement and improvement of information retrieval ranking, document ranking, and SEO performance.
What Is Document Ranking in Information Retrieval?
Document ranking is the process in information retrieval (IR) that sorts a document collection in response to a query, ordering documents from most to least relevant so the best results appear first. Document ranking in information retrieval defines the core optimization task where a system receives a query q and a document set D, then produces an ordered list where the highest-relevance documents occupy top positions. The document ranking meaning centers on relevance scoring, where ranking algorithms assign quantitative scores to each document based on how well the document satisfies the query intent.
What is a document in document ranking information retrieval? A document in document ranking refers to any retrievable unit of indexed information with structured or unstructured content attributes. A document in document ranking includes web pages, PDFs, product listings, images, videos, and forum posts (web page, article, PDF, product listing, image, video, forum post). The document entity acts as the ranking unit, where the ranking system evaluates the entire document as a single relevance object. The document representation contains textual features, metadata fields, and embedded signals that ranking algorithms process during scoring.
What is the difference between document retrieval and ranking documents in a search engine? Document retrieval identifies matching documents, while ranking documents determines the order of those documents based on relevance scores. Document retrieval in information retrieval focuses on recall, where the system fetches all documents that match query terms or conditions. Ranking documents in a search engine focuses on precision, where the system prioritizes the most relevant documents at the top of the results list. The retrieval stage produces a candidate set, and the document ranking stage reorders that set using scoring functions and ranking models.
What signals define document ranking meaning in ranking algorithms? Document ranking operates on relevance signals that quantify how well a document satisfies a query using measurable attributes. Document ranking signals include lexical relevance, semantic relevance, authority metrics, user behavior data, and technical factors (term frequency, embeddings, backlinks, click-through rate, page speed). The ranking algorithm aggregates these signals into a scoring function, where each signal contributes a weighted value to the final ranking score.
How did document ranking in information retrieval develop over time? Document ranking evolved from early probabilistic and mathematical models into modern machine-learning ranking systems with multi-signal integration. Document ranking history traces to Wassily Leontief’s 1941 iterative valuation model, which introduced recursive scoring logic. The document ranking field advanced through the Maron and Kuhns probabilistic model in 1960, vector space models and TF-IDF in the 1970s, BM25 in 1994, and PageRank in 1998. Modern document ranking systems apply machine learning and transformer-based models to refine relevance estimation across large-scale indexes.
Where does document ranking fit in a search engine pipeline? Document ranking is the final stage in the search pipeline after crawling and indexing, where the system orders indexed documents for query response. The search engine pipeline consists of three stages: crawling collects documents, indexing structures documents into searchable formats, and document ranking orders documents based on relevance. The ranking stage consumes indexed data and query features, then produces a sorted results list for presentation.
What is the difference between document-level ranking and passage ranking? Document-level ranking evaluates the entire document as the relevance unit, while passage ranking evaluates individual sections within a document independently. Document-level ranking assigns a single score to the full document based on global features. Passage ranking assigns scores to smaller text segments, where each passage acts as a semi-independent relevance unit. Passage ranking improves precision for long documents, while document ranking maintains holistic evaluation of document context.

What Is the Difference Between Document Ranking and Page Ranking?
The difference between document ranking and page ranking is that document ranking evaluates query-specific relevance using document content, while page ranking evaluates overall page authority using link structure. Document ranking in information retrieval scores documents based on how well document content matches a query, while PageRank assigns a global importance score to a page based on backlinks and link distribution.
What are the key differences between document ranking and page ranking across core features?
Document ranking and page ranking differ across 10 core features that define relevance scoring and authority scoring. The comparison is structured below.
| Feature / Aspect | Document Ranking (BM25) | Page Ranking (PageRank) |
|---|---|---|
| Nature of metric | Measures query-dependent relevance using content signals. | Measures global importance using link authority signals. |
| Primary input | Uses document content (term frequency, proximity, and semantic relationships). | Uses link structure (backlink quantity, backlink quality). |
| Core mechanism | Applies probabilistic scoring models (TF-IDF, BM25). | Applies recursive link analysis with PageRank formula. |
| Keyword dependency | Operates as keyword-dependent and query-sensitive. | Operates as query-independent and static per page. |
| Methodology | Uses content analysis and document length normalization. | Uses link graph evaluation and authority propagation. |
| Formula model | Computes scores using term frequency and inverse document frequency. | Computes PR(A) = (1-d) + d (PR(T1)/C(T1) + PR(Tn)/C(Tn)), where d = 0.85. |
| Application | Drives relevance ranking in information retrieval systems. | Evaluates page credibility and trust in web search. |
| Historical context | Evolved through probabilistic and vector space models. | Introduced in 1996 by Larry Page and Sergey Brin. |
| Visibility | Directly determines SERP positions. | Functions as an internal signal after public updates ended in 2016. |
| Strength | Excels in precise relevance scoring using content signals. | Excels in authority evaluation using backlink signals. |
When does document ranking outperform page ranking? Document ranking outperforms page ranking in query-specific relevance scenarios where content signals determine ranking quality. Document ranking prioritizes exact term matching and semantic alignment, which increases precision for targeted queries (Python web development best practices). Document ranking evaluates new documents effectively because content signals exist without backlink dependency.
When does page ranking outperform document ranking? Page ranking outperforms document ranking in authority-driven scenarios where backlink signals determine credibility. Page ranking evaluates link networks to identify authoritative pages, which improves trust assessment in broad web search. Page ranking reduces low-quality results because weak backlink profiles lower authority scores.
Why Does Document Ranking Matter for SEO?
Document ranking matters for SEO because higher-ranked documents capture the majority of visibility, clicks, and traffic from search engines. Document ranking in SEO determines where a document appears in search results, and position directly controls how much traffic a document receives, how often users interact with it, and how much business value it generates.
How does traffic distribution prove that document ranking matters? Document ranking controls traffic distribution because 94% of users interact only with first-page results. Document ranking concentrates visibility on the first page, where 94% of total organic traffic occurs. The second page receives 4% of traffic, and all remaining pages receive 2%. This distribution shows that documents outside the top rankings remain effectively unseen.
Why do click-through rates make document ranking critical? Document ranking impacts click-through rates because higher positions receive exponentially more clicks. Document ranking assigns the top position an average of 39.8% of total clicks, which increases to 42.9% with a featured snippet. The second position receives 18.7%, and the third position receives 10.2%, while the tenth position drops to 1.6%. This pattern shows that rank position directly determines user engagement.
What is the role of document ranking in total website traffic? Document ranking drives website traffic because over 53% of total traffic originates from organic search. Document ranking positions determine how much of that organic traffic reaches a website. Organic traffic produces higher engagement and conversion outcomes compared to paid channels, which increases the impact of ranking performance.
How does document ranking influence revenue and cost efficiency? Document ranking affects economic outcomes because top positions reduce reliance on paid advertising and generate qualified traffic. Document ranking in the top 3 positions for transactional queries offsets thousands of dollars in PPC spend. High-ranking documents attract users with strong intent, which increases lead generation, product sales, and conversion efficiency.
Why does document ranking affect brand authority and trust? Document ranking builds brand authority because consistent high positions signal credibility to users. Document ranking creates repeated exposure in top results, which reinforces perceived reliability. Search engines associate high-ranking documents with quality signals, and users interpret top-ranked results as more trustworthy sources.
Why is understanding document ranking important for SEO strategy? Understanding document ranking defines SEO strategy because ranking determines visibility, indexing outcomes, and optimization priorities. Document ranking analysis identifies which documents perform, which queries drive impressions, and where optimization gaps exist. Ranking data guides actions across content optimization, technical SEO, and authority building, which improves long-term visibility and performance.
How Does Document Ranking Work?
Document ranking works by retrieving matching documents, scoring each document using relevance signals, and ordering documents from highest to lowest relevance. Document ranking in information retrieval executes a structured pipeline where a query interacts with an indexed document collection, and ranking algorithms compute scores that determine final result positions.
What components are required for document ranking to function? Document ranking requires 5 core components. The components are listed below.
- Query. The query represents the information need and initiates document ranking.
- Document collection. The document collection stores all indexed documents for retrieval.
- Preprocessing. Preprocessing transforms documents through tokenization, normalization, and text standardization.
- Ranking algorithms. Ranking algorithms (TF-IDF, BM25, PageRank) define how scores are computed.
- Relevance features. Relevance features include term frequency, document structure, and link data.
What happens during initial document retrieval? Initial document retrieval filters the document collection into a smaller candidate set based on query matching. Document retrieval applies Boolean logic and inverted indexes to identify documents containing query terms. The retrieval stage reduces computational load by selecting only potentially relevant documents for scoring.
How does document scoring assign relevance values? Document scoring assigns a numerical relevance score to each document using weighted features. Document scoring evaluates term frequency, document length, semantic similarity, and authority signals. Each document receives a score that represents how well the document matches the query intent.
What role does the vector space model play in ranking documents? The vector space model represents documents and queries as vectors and ranks documents using cosine similarity. The vector space model converts text into numerical vectors where each dimension corresponds to a term. Cosine similarity measures the angle between vectors, and higher similarity values indicate stronger relevance between the query and the document.
How does ranking and re-ranking finalize document order? Ranking orders documents by descending relevance scores, and re-ranking refines the order using additional signals. The ranking stage sorts documents based on computed scores. Re-ranking introduces additional features (user behavior, freshness, diversity) to adjust positions and improve result quality.
What are common failure cases in document ranking systems? Document ranking systems fail in 3 main cases. The cases are listed below.
- Query ambiguity. Ambiguous queries produce mixed intent results, which reduces relevance accuracy.
- Spam manipulation. Manipulated signals (keyword stuffing, link schemes) distort ranking scores.
- Outdated information. Stale documents rank when indexing and freshness signals are weak.
What Are TF-IDF and BM25, and How Do They Rank Documents?
TF-IDF (Term Frequency–Inverse Document Frequency) and BM25 (Okapi BM25) are document ranking algorithms that assign numerical relevance scores to documents based on term importance and distribution within a corpus. TF-IDF and BM25 belong to information retrieval ranking models where each document receives a score calculated from term frequency and inverse document frequency, which determines how documents rank for a given query.
What is TF-IDF, and how does TF-IDF rank documents? TF-IDF is a term weighting model that ranks documents by multiplying term frequency by inverse document frequency to emphasize discriminative terms. TF-IDF (Term Frequency–Inverse Document Frequency) measures how often a term appears in a document and how rare that term is across the document collection. The TF-IDF score increases when a term appears frequently in one document but appears rarely across other documents. This scoring method pushes documents with highly relevant and unique terms toward higher ranking positions.
What is BM25, and how does BM25 rank documents? BM25 is an advanced probabilistic ranking function that improves TF-IDF by applying term frequency saturation and document length normalization. BM25 (Okapi BM25) calculates relevance using controlled term frequency growth, where repeated terms produce diminishing returns based on parameter k1 (≈ 1.2). BM25 normalizes document length using parameter b (≈ 0.75), which prevents longer documents from receiving inflated scores. This adjustment produces more balanced ranking outcomes across documents of different lengths.
What components define TF-IDF and BM25 scoring mechanisms? TF-IDF and BM25 rely on 3 core components. The components are listed below.
- Term frequency (TF). Term frequency measures how often a term appears in a document and increases relevance proportionally.
- Inverse document frequency (IDF). Inverse document frequency measures how rare a term is across the corpus and reduces the weight for common terms.
- Document normalization. Document normalization adjusts scores based on document length and term distribution, which BM25 formalizes explicitly.
Why does BM25 outperform TF-IDF in document ranking systems? BM25 outperforms TF-IDF because BM25 controls term frequency growth and adjusts for document length, which improves ranking accuracy. BM25 prevents keyword repetition from inflating relevance scores through saturation. BM25 ensures fair comparison between short and long documents through normalization. These improvements produce more stable and accurate rankings in large-scale search systems.
Where are TF-IDF and BM25 used in modern search systems? TF-IDF and BM25 are used in search engines, digital libraries, and large-scale retrieval systems to rank documents efficiently. TF-IDF operates in lightweight systems for keyword extraction and small-scale ranking tasks. BM25 operates in production search systems (Elasticsearch, Solr, Azure Cognitive Search) where accurate relevance scoring is required. BM25 functions as a baseline ranking model in many modern retrieval and RAG (Retrieval-Augmented Generation) systems.
What Is PageRank and How Does It Contribute to Document Ranking?
PageRank is a link-based ranking algorithm that assigns an importance score to each document based on the quantity and quality of incoming links. PageRank refers to a graph-based algorithm developed by Larry Page and Sergey Brin in 1998, where each document receives a probability score that represents how likely a random surfer is to reach that document through links. PageRank contributes to document ranking by injecting authority signals into ranking algorithms, which influence how documents rank in a search engine.
What core principle defines how PageRank calculates importance? PageRank calculates importance by transferring authority through links, where links from important documents pass a higher value. PageRank treats each link as a vote, but PageRank weights each vote based on the importance of the linking document. A document receives a higher PageRank score when many high-authority documents link to it. This recursive structure ensures that authority propagates across the link graph.
How is PageRank mathematically computed? PageRank computes importance using an iterative formula where each document distributes its score across outgoing links. PageRank defines PR(A) = (1 − d) + d (PR(T1)/C(T1) + PR(Tn)/C(Tn)), where d = 0.85 represents the damping factor. The PageRank algorithm initializes equal scores across documents, then repeatedly updates scores using power iteration until convergence reaches a threshold (ε ≈ 0.0005). This process produces a stable probability distribution across all documents.
How does the damping factor improve PageRank stability? The damping factor improves PageRank stability by introducing random jumps that prevent rank sinks and ensure convergence. The damping factor (0.85) assigns 85% probability to the following links and 15% probability to jumping to a random document. This mechanism resolves dead ends and spider traps, which would otherwise absorb all ranking weight and break the system.
What role does PageRank play in document ranking systems? PageRank contributes to document ranking by providing an authority score that complements content-based relevance scoring. Document ranking systems combine PageRank scores with relevance signals (TF-IDF, BM25, and semantic similarity). PageRank increases the ranking position of documents with strong backlink profiles, while content-based models ensure query relevance. This combination produces balanced rankings based on both relevance and authority.
How has PageRank evolved in modern search systems? PageRank evolved into a component within multi-signal ranking systems that integrate link, content, and behavior signals. PageRank introduced improvements (reasonable surfer model, seed-based trust propagation, link attributes: nofollow, ugc, sponsored). Modern systems use PageRank as one signal among many, where link quality, topical relevance, and click behavior influence final rankings.
What factors influence PageRank scores in document ranking? PageRank scores depend on 4 main factors. The factors are listed below.
- Link quantity. A higher number of incoming links increases the PageRank score.
- Link quality. Links from high-authority documents pass a stronger PageRank value.
- Link attributes. Attributes (nofollow, sponsored, ugc) reduce or alter PageRank flow.
- Link position. Links placed in prominent positions pass more PageRank than hidden links.
How do internal and external links affect PageRank contribution? Internal links distribute PageRank within a site, while external links define authority relationships across the web. Internal links transfer PageRank between documents on the same site, which increases the visibility of important pages. External links connect documents across domains, which establishes authority and trust signals in the broader link graph.
What Are the Main Types of Document Ranking Signals?
The main types of document ranking signals are 6 core categories that define how ranking algorithms evaluate relevance, authority, quality, and interaction. Document ranking signals refer to measurable attributes that ranking systems use to score and order documents in a search engine. These signals operate at the content level, page level, site level, and system level, which ensures accurate ranking across different contexts.
What are the 6 main types of document ranking signals? The 6 main types of document ranking signals are listed below.
- Content signals. Content signals measure how well document content matches query intent using lexical and semantic relevance.
- Link signals. Link signals measure document authority using backlinks, PageRank, and anchor text relationships.
- User experience signals. User experience signals measure technical performance and usability (Core Web Vitals, page speed, mobile usability).
- User interaction signals. User interaction signals measure engagement (click-through rate, dwell time, bounce rate).
- Technical and structural signals. Technical and structural signals measure crawlability, indexability, structured data, and site architecture.
- System-level and model signals. System-level and model signals measure outputs from ranking systems (BERT, RankBrain, neural matching, spam systems).
What defines content signals in document ranking? Content signals evaluate relevance by analyzing term usage, semantic meaning, and document quality. Content signals include keyword presence, TF-IDF weighting, BM25 scoring, entity coverage, and topical depth. Content signals determine how closely a document aligns with a query, which directly affects ranking position.
What defines link signals in document ranking? Link signals evaluate authority by analyzing the quantity, quality, and context of backlinks. Link signals include PageRank, backlink authority, anchor text, and internal linking structure. Link signals increase ranking strength when high-authority documents transfer link equity.
What defines user experience signals in document ranking? User experience signals evaluate performance and usability through measurable technical metrics. User experience signals include Core Web Vitals (LCP, INP, CLS), mobile-friendliness, HTTPS security, and page speed. User experience signals affect ranking because fast and stable pages improve accessibility and satisfaction.
What defines user interaction signals in document ranking? User interaction signals evaluate engagement by measuring how users interact with ranked documents. User interaction signals include click-through rate, dwell time, and bounce rate. User interaction signals indicate whether a document satisfies user intent after ranking.
What defines technical and structural signals in document ranking? Technical and structural signals evaluate how well a document is crawled, indexed, and structured. Technical signals include crawl frequency, indexation status, structured data markup, URL structure, and internal linking. Technical signals ensure that ranking systems can access and interpret documents correctly.
What defines system-level and model signals in document ranking? System-level and model signals evaluate outputs from ranking systems and machine learning models. System-level signals include BERT, RankBrain, neural matching, spam detection systems, and ranking system layers. These signals interpret language, detect spam, and refine ranking decisions using learned patterns.
How are document ranking signals grouped by signal type? Document ranking signals group into 3 signal types. The signal types are listed below.
- On-site signals. On-site signals originate from document content and site structure (content, UX, technical signals).
- Offsite signals. Offsite signals originate from external sources (backlinks, brand mentions, authority signals).
- Hybrid signals. Hybrid signals combine onsite and offsite data (user interaction, model-based signals, contextual relevance).
How Does Google Rank Documents?
Google ranks documents using a multi-system ranking architecture where multiple specialized systems generate signals that combine into a final ranking score for each document. Google document ranking systems do not rely on a single Google ranking algorithm, but instead operate as a layered system where each component evaluates relevance, authority, quality, and usability. Google ranking systems 2025 confirm that each document receives an individual evaluation, while site-level systems influence the upper limit of ranking potential.
What are the core ranking systems in Google’s multi-system ranking? Google’s core ranking systems form the foundational layer that determines document relevance for all queries. The core systems are listed below.
- BERT (Bidirectional Encoder Representations from Transformers). BERT interprets full sentence context, which improves relevance by understanding word relationships within queries and documents.
- Neural Matching. Neural Matching connects concepts between queries and documents, which enables ranking even without exact keyword matches.
- RankBrain. RankBrain processes unfamiliar queries using machine learning, which maps queries to relevant document types based on historical patterns.
- MUM (Multitask Unified Model). MUM processes text, images, and video, which supports complex and multi-step query resolution.
- Passage Ranking. Passage Ranking evaluates sections within a document, which assigns relevance scores at the passage level and contributes to the overall document ranking.
What site-wide and quality systems influence Google document ranking? Google’s site-wide and quality systems evaluate overall site quality and enforce ranking constraints across documents. The systems are listed below.
- Helpful Content System. The Helpful Content System classifies site quality and reduces visibility for sites with high proportions of low-value content.
- SpamBrain. SpamBrain detects spam patterns (link spam, content spam), which demote manipulated documents.
- Page Experience. Page Experience evaluates Core Web Vitals (LCP, INP, CLS), HTTPS, and mobile-friendliness, which influence usability-based ranking signals.
How does Google combine signals to rank documents? Google combines signals by aggregating outputs from multiple systems into a composite ranking score for each document. Google multi-system ranking processes content relevance, link authority, user interaction, and technical performance simultaneously. Each system contributes weighted signals, and the ranking engine orders documents based on the final combined score.
How are documents evaluated in Google ranking systems? Google evaluates documents individually using page-level signals, while site-wide systems define ranking thresholds. Google document ranking systems assign scores at the document level, which means high-quality pages can rank even within weaker sites. Site-wide classifiers influence visibility limits, but individual document quality determines final ranking positions.
How to Improve Document Ranking?
Document ranking improves through 6 core methods that increase relevance precision, authority clarity, retrieval quality, and technical interpretability. Document ranking improvement requires changes across retrieval logic, machine learning models, entity understanding, generative retrieval pipelines, and document structure. The methods below target the main ranking weaknesses that reduce visibility and lower result quality.
What are the 6 main ways to improve document ranking?
The 6 main ways to improve document ranking are listed below.
- Implement re-ranking.
- Leverage LLMs for optimization.
- Apply Learning to Rank (LTR).
- Focus on entity-based indexing.
- Optimize Retrieval-Augmented Generation (RAG).
- Enhance metadata and structure.
1. Implement Re-ranking
Re-ranking improves document ranking by reordering an initial candidate set with a more precise relevance model, which increases top-result accuracy. Re-ranking acts as a second ranking pass after initial retrieval. The first pass retrieves 20-100 candidate documents with BM25 or vector similarity, and the second pass re-scores those documents with a stronger model. Re-ranking improves Mean Reciprocal Rank (MRR) by 10%-30% and improves NDCG@10 by 15%-40% in many retrieval pipelines.
What does re-ranking change in the ranking process? Re-ranking changes the order of retrieved documents without changing the candidate set. Re-ranking evaluates query-document fit with richer context, which corrects weak initial ordering. A cross-encoder re-ranker compares the full query and full candidate text directly, which produces higher precision than raw cosine similarity from precomputed embeddings.
What are the main ranking gains from re-ranking? Re-ranking increases precision at the top of the result list, reduces irrelevant retrieval, and improves answer quality in RAG systems. Re-ranking reduced irrelevant document retrieval by 30% in legal workflows and reduced irrelevant responses by 40% in customer support systems. BERT-based re-rankers increased support resolution rates by 25%-30%, and Jina Reranker produced a 20% boost in response accuracy.
How should re-ranking be implemented? Implement re-ranking with a 2-stage retrieval pipeline that separates recall from precision. Firstly, retrieve 50-100 candidates with BM25, dense retrieval, or hybrid retrieval. Secondly, re-score the candidate set with a cross-encoder or domain-tuned re-ranker. Thirdly, keep the top 5-10 documents for final ranking or LLM context injection. Re-ranking usually adds 50-150 ms latency for 50 documents, so cap candidate volume and cache repeat query-document scores.
2. Leverage LLMs for Optimization
Leveraging Large Language Models (LLMs) for optimization improves document ranking by interpreting intent, expanding queries, and re-evaluating relevance with deeper semantic context. LLM optimization improves ranking quality because LLMs analyze the full relationship between a query and a document instead of relying only on keyword overlap. LLM optimization strengthens ranking for ambiguous, conversational, and multi-step queries.
What does LLM optimization do in ranking systems? LLM optimization rewrites queries, infers missing constraints, and scores documents against full intent. A query like “best laptops for coding” becomes a richer intent representation around CPU performance, 16 GB RAM, and battery life. That richer representation increases the ranking score of documents that match the implied task, not just the literal words.
What ranking methods use LLMs directly? LLM ranking methods include cross-encoder re-ranking, comparative ranking, and summary-assisted retrieval. RefRank compares each candidate against a fixed reference document and reduces ranking cost to O(n), which improves efficiency over pairwise O(n²) ranking. LLM-generated summaries improve archival document ranking because summaries add context to noisy OCR text and make documents easier to classify and retrieve.
How should LLMs be used for ranking optimization? Use LLMs after initial retrieval, not as the only retrieval layer. Run BM25, vector retrieval, or hybrid retrieval first. Pass the top candidate set into an LLM re-ranker or cross-encoder for semantic reordering. Add LLM-generated summaries to weak or noisy documents, especially archived PDFs and OCR-heavy records, because richer metadata improves discoverability.
3. Apply Learning to Rank (LTR)
Learning to Rank (LTR) improves document ranking by training a machine learning model to order documents based on real relevance judgments instead of manual weights. LTR replaces static heuristic weighting with learned ranking logic. LTR models score documents using feature sets that reflect document relevance, query relationship, popularity, freshness, and engagement.
What problem does Learning to Rank solve? Learning to Rank solves the limits of manual scoring because manual weights do not capture feature interaction or query-specific importance. A manual scoring formula treats features too uniformly. An LTR model learns which features matter most for each ranking pattern, which produces stronger ordering at the top of the result list.
What inputs power an LTR model? LTR models depend on judgment lists, ranking features, and supervised learning objectives. Judgment lists assign relevance grades on a 0-4 scale. Features include BM25, TF-IDF, click-through rate, publication date, title score, popularity, rating, and query length. LambdaMART and gradient-boosted decision trees are standard LTR models because tree-based ranking models perform strongly in production search systems.
How should LTR be implemented? Implement LTR as a rescore layer after fast first-pass retrieval. Firstly, retrieve a broad set with BM25 or a multi-match query. Secondly, extract ranking features for the top results. Thirdly, rescore the top 100 or similar window with a trained LTR model optimized for nDCG or MAP. Keep a separate test set so the model is evaluated on unseen queries, not only on training judgments.
4. Focus on Entity-Based Indexing
Entity-based indexing improves document ranking by organizing content around clearly defined concepts instead of isolated keywords. Entity-based indexing gives search engines stronger signals about topic meaning, topic relationships, and content intent. An entity is a singular, well-defined concept (person, place, product, organization, idea), and entity clarity improves how ranking systems interpret relevance.
How do entities improve ranking precision? Entities improve ranking precision because search engines score documents by concept coverage and concept relationships, not only by term repetition. Search engines identify main entities, supporting entities, and salience patterns inside a document. That structure improves document scoring for broad, conversational, and semantically related queries.
What ranking benefits come from entity optimization? Entity optimization increases broader ranking coverage, improves contextual relevance, and strengthens trust signals. Entity optimization expands ranking beyond one keyword string because a document can rank across connected searches that share the same conceptual context. Entity optimization improved impressions by 440%, and clicks by 52% in one InLinks case, and Ling App increased domain authority from 26 to 43 after entity-driven optimization.
How should entity-based indexing be implemented? Implement entity-based indexing by mapping primary entities, related entities, and structured definitions across the document. Audit competitor entity coverage first. Add schema markup that disambiguates the main entity. Place the primary entity early, repeat the full entity name naturally, connect the entity to related entities, and strengthen internal links around shared entity clusters. Avoid entity stuffing because forced repetition weakens readability and intent alignment.
5. Optimize Retrieval Augmented Generation (RAG)
Optimizing Retrieval-Augmented Generation (RAG) improves document ranking by increasing retrieval accuracy, chunk relevance, and answer grounding before generation. RAG ranking quality depends on embeddings, chunking, metadata, vector search, and re-ranking. Better RAG optimization produces more accurate document selection and lowers irrelevant context injection into the final answer.
What elements define RAG ranking quality? RAG ranking quality depends on 5 main elements: embeddings, chunking, metadata, retrieval logic, and re-ranking. Better embeddings improve semantic matching. Better chunking preserves meaning. Better metadata improves filtering. Better retrieval logic improves recall. Better re-ranking improves top-result precision.
What evidence shows RAG optimization improves ranking? RAG optimization improves response quality by 10%-30% in many implementations. Jina Reranker increased response accuracy by 20%. Domain-trained legal re-rankers reduced irrelevant retrieval by 30%. Hybrid customer support systems reduced irrelevant responses by 40%. The Paragon study reported a 2.5% lift in average answer relevancy and a 51% drop in irrelevant answers in one tested configuration.
How should RAG be optimized for ranking? Optimize RAG with hybrid retrieval, semantic chunking, metadata enrichment, and selective re-ranking. Firstly, combine dense retrieval with keyword retrieval to improve recall. Secondly, segment documents at semantic boundaries and enrich chunks with metadata fields (source, section, topic, entity, date). Thirdly, re-rank the retrieved chunk set with a stronger model before generation. Increase retrieved depth only where answer quality improves, because excessive context lowers precision.
6. Enhance Metadata and Structure
Enhancing metadata and structure improves document ranking by making documents easier to interpret, index, classify, and display in search systems. Metadata provides machine-readable descriptions of a document, and structure gives the document a clear hierarchy. Strong metadata and strong structure improve indexing accuracy, click-through potential, and search visibility.
What metadata elements influence document ranking the most? The main metadata and structure elements are title tags, meta descriptions, header tags, alt text, URLs, and structured data. Title tags influence result selection and click appeal. Meta descriptions improve click-through rate. Header tags clarify hierarchy. Alt text defines the image’s meaning. URLs reinforce topic labeling. Structured data gives search engines explicit entity and content classification.
How does metadata improve retrieval and ranking systems? Metadata improves retrieval and ranking systems because metadata adds context that raw text alone does not provide. Metadata fields like source, date, section title, page number, chunk ID, and entity label improve filtering and explainability in both SEO systems and RAG systems. Better metadata quality improves discovery, traceability, and ranking accuracy.
How should metadata and structure be enhanced? Enhance metadata and structure with consistent field design, descriptive markup, and clear heading hierarchy. Write keyword-aligned title tags and intent-matched meta descriptions. Use one H1 and logical H2-H3 nesting. Add descriptive alt text and short, readable URLs. Apply schema.org markup to define entities and content types. Standardize metadata fields across the site, train teams on field usage, and audit implementation regularly because inconsistent metadata weakens ranking signals.
What Are the Best Tools for Document Ranking Analysis and Optimization?
The best tools for document ranking analysis and optimization are 5 SEO tools that measure relevance, authority, technical performance, and user behavior at the document level. Document ranking tools identify which documents rank, why documents rank, and what changes improve ranking performance across the main signal categories. Search Atlas ranks first because Search Atlas combines rank tracking, content optimization, technical analysis, and backlink analysis in one workflow.
What are the 5 best tools for document ranking analysis and optimization? The 5 best SEO ranking tools for document ranking analysis and optimization are listed below.
- Search Atlas. Search Atlas is the best tool for document ranking optimization because Search Atlas covers relevance signals, authority signals, and technical signals in one platform. Search Atlas includes Rank Tracker (feature) for position monitoring, Content Genius (feature) for on-page relevance and entity optimization, Site Audit (feature) for technical signal analysis, Backlink Analyzer (feature) for link authority assessment, and On-Page Optimizer (feature) for real-time relevance scoring against SERP competitors. Search Atlas gives a complete workflow for end-to-end document ranking management.
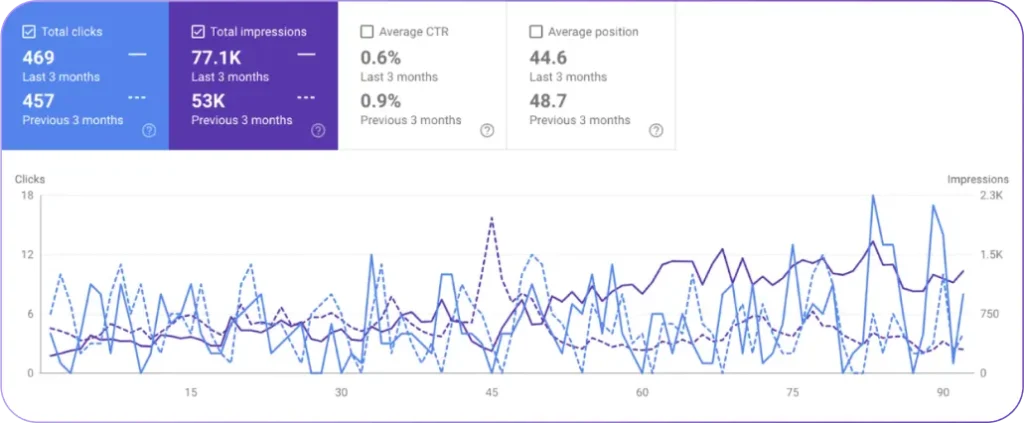
- Google Search Console. Google Search Console provides document-level ranking data directly from Google. Google Search Console shows queries, positions, impressions, clicks, and CTR for each URL. Google Search Console identifies ranking opportunities where impressions are high and CTR is low, which exposes title tag and meta description gaps. Google Search Console tracks Core Web Vitals at the URL level.
- Google Analytics 4. Google Analytics 4 measures document-level user behavior after rankings generate traffic. Google Analytics 4 reports organic sessions, engagement rate, average engagement time, and conversion events. Google Analytics 4 separates documents that rank from documents that rank and produce business outcomes.
- Semrush. Semrush analyzes competitor document rankings and keyword gaps using ranking and visibility data. Semrush includes Position Tracking (feature) for monitoring ranking changes across a defined keyword set, which shows how document positions shift over time. Semrush identifies which competitor documents rank for target queries and highlights content gaps that require optimization.
- Ahrefs. Ahrefs analyzes backlink profiles and competitor document authority using link-based data. Ahrefs includes backlink analysis features that evaluate referring domains, anchor text, and link strength, which determine PageRank influence. Ahrefs reveals which documents gain ranking strength from backlinks and which link-building gaps exist.
- Screaming Frog SEO Spider. Screaming Frog SEO Spider runs deep technical crawls at the document level. Screaming Frog SEO Spider identifies crawlability issues, indexability issues, duplicate content, missing title tags, duplicate meta tags, heading hierarchy errors, redirect chains, and internal link weaknesses. These issues affect individual document rankings directly.
Why does Search Atlas rank first among document ranking tools? Search Atlas ranks first because Search Atlas combines the broadest set of document ranking analysis tools inside one platform. Search Atlas tracks rankings, scores content relevance, audits technical issues, and evaluates backlinks without splitting the workflow across multiple tools. Search Atlas On-Page Optimizer (feature) and Search Atlas Site Audit (feature) create direct actions for document-level and site-level improvements, which makes Search Atlas the strongest single-platform option for document ranking analysis tools.
Why are multiple tools required for document ranking analysis? Document ranking analysis requires multiple tools because no single tool covers every ranking signal with equal depth. Search Atlas covers the widest signal range in one system. Google Search Console provides the ground-truth ranking data. Google Analytics 4 connects rankings to engagement and conversions. Together, these tools create a complete picture of document-level SEO performance.
How Do SEO Tools Measure Document Ranking Performance?
SEO tools measure document ranking performance by tracking visibility, position, engagement, authority, and technical health metrics at the document level. SEO tools collect ranking data, traffic data, and backlink data, then map those signals to specific URLs to evaluate how each document performs in search results. The first-ranked result receives 31.7% average CTR, which shows how ranking position directly affects performance outcomes.
What key metrics do SEO tools track for document ranking performance? SEO tools track 12 core metrics that define document ranking performance. The metrics are listed below.
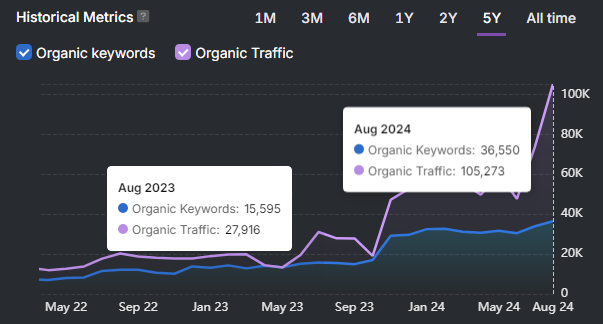
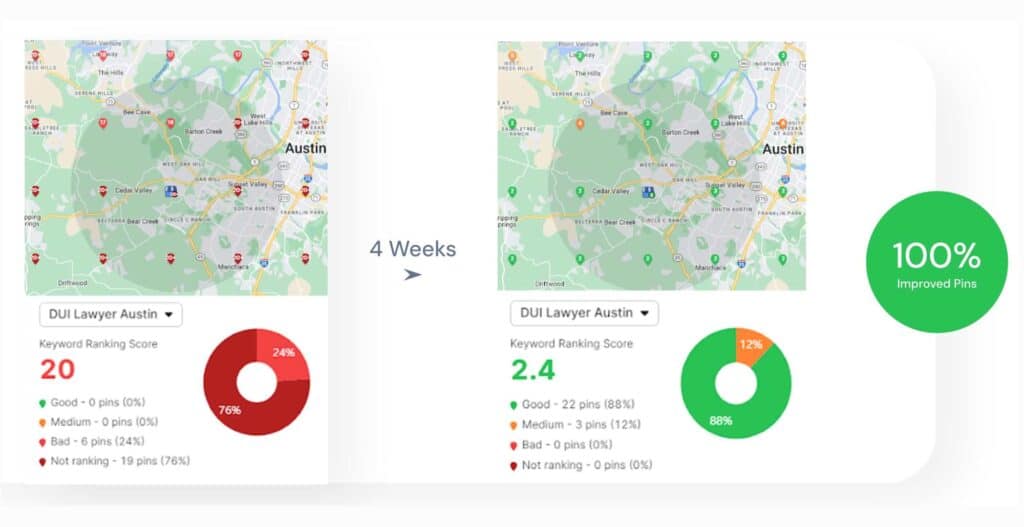
- Keyword rankings. Keyword rankings measure document position on the SERP for target queries.
- Organic traffic. Organic traffic measures visits generated from search engines.
- Click-through rate (CTR). CTR measures clicks divided by impressions for a document.
- Impressions. Impressions measure how often a document appears in search results.
- Backlinks. Backlinks measure incoming links pointing to a document.
- Referring domains. Referring domains measure unique domains linking to a document.
- Search visibility. Search visibility measures overall ranking presence across keyword sets.
- Domain Authority (DA). Domain Authority predicts ranking strength on a 1-100 scale.
- Core Web Vitals. Core Web Vitals measure performance (LCP, INP, CLS).
- Crawl errors. Crawl errors identify indexing and accessibility issues.
- Share of voice. Share of voice measures SERP ownership across tracked keywords.
- Answer Engine Visibility. Answer Engine Visibility measures presence in AI-driven results.
How do SEO tools collect and report document ranking data? SEO tools collect data from search engines, crawlers, and user behavior tracking systems, then map the data to document-level performance. Google Search Console (tool) reports queries, clicks, impressions, CTR, and average position for each URL. Google Analytics 4 (tool) reports sessions, engagement rate, and conversions from organic traffic. Semrush (tool) and Ahrefs (tool) track rankings, backlinks, and competitor performance using large keyword and link databases. Screaming Frog SEO Spider (tool) audits crawlability, indexability, and technical signals that affect ranking.
What challenges affect measurement accuracy in document ranking? Measurement accuracy is limited by 6 main challenges: algorithm changes, zero-click results, privacy restrictions, fragmented data, delayed impact, and personalization. Search engines update ranking systems frequently, which shifts metrics. Zero-click results reduce traffic even when impressions increase. Privacy rules limit tracking accuracy. Different tools report different values. SEO changes take 3-6 months to show impact. Personalized SERPs create variation across users and devices.
What Metrics Are Used to Evaluate Document Ranking Performance?
Document ranking performance uses ranking metrics, engagement metrics, and business metrics to evaluate result quality and effectiveness. Ranking evaluation measures how well a system orders documents so that the most relevant results appear at the top positions.
What are the core ranking evaluation metrics? The 7 core ranking evaluation metrics are listed below.
- Precision@k. Precision@k measures the proportion of relevant documents in the top k results.
- Recall@k. Recall@k measures how many relevant documents appear in the top k results out of all relevant documents.
- F1-score. F1-score balances precision and recall into a single metric.
- Mean Reciprocal Rank (MRR). MRR measures how early the first relevant document appears.
- Mean Average Precision (MAP@k). MAP@k measures average precision across multiple queries.
- Discounted Cumulative Gain (DCG). DCG measures ranking quality using graded relevance and position discounting.
- Normalized Discounted Cumulative Gain (nDCG). nDCG normalizes DCG to a 0-1 scale for comparability.
What behavioral and business metrics evaluate ranking performance? Behavioral and business metrics evaluate how ranking performance translates into user engagement and outcomes. CTR measures click efficiency. Conversion rate measures how many visits lead to actions. Session length and dwell time measure engagement quality. Revenue and Average Revenue Per User (ARPU) measure financial impact. Session abandonment rate, session success rate, and zero result rate measure search experience quality.
Why do ranking metrics focus on top positions? Ranking metrics focus on top positions because users interact with a limited number of results, which concentrates value at higher ranks. Metrics use a cutoff parameter (k) because most interactions occur within the top results. Metrics like nDCG and MRR assign higher weight to earlier positions, which reflects real user behavior where top-ranked documents receive the majority of attention.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}