

If you’re comparing PromptMonitor IO alternatives in 2026, the best fit for most SEO and content teams is SearchAtlas — it combines multi‑model LLM visibility with a full SEO and GEO stack (and AI answer engine optimization (AEO)). Other strong options include Helicone and LangSmith for developer‑grade observability, and PromptPerfect or Promptmetheus for prompt engineering and optimization.
Prompt monitoring and LLM visibility platforms track how generative models cite, surface, and repurpose web content. In this guide, we compare the best PromptMonitor IO alternatives in 2026, including developer‑focused prompt monitoring tools, LLM observability platforms, and SEO‑first visibility suites. You’ll see how each option handles multi‑model tracking, citation‑share analytics, AI crawler data, and prompt engineering integrations—and where SearchAtlas fits in as an LLM visibility and GEO platform.
Methodology
This comparison evaluates tools on practical signals relevant to SEO and engineering teams: supported models and assistants, depth of analytics and observability, SEO and CMS integrations, agency and white‑label support, and developer features (tracing, logs, and evaluation). Where possible we cross‑checked vendor docs, public demos, and third‑party reviews to surface realistic strengths and trade‑offs.
This article shows marketers, SEOs, and agency teams how to evaluate AI prompt monitoring tools. You’ll learn to map feature sets to business needs and prioritize workflows that actually improve your generative engine optimization (GEO) outcomes. We’ll cover which capabilities matter most—multi-model tracking, citation share metrics, AI crawler analytics, and prompt engineering integrations—and how those capabilities translate into measurable AI traffic and brand mentions.
You’ll find top tool attributes, prompt monitoring and prompt engineering software to pair with LLM visibility platforms, agency automation considerations, buyer decision frameworks, and real-world ROI examples you can replicate. Throughout the piece we reference practical checklists and comparison tables to make vendor shortlisting faster while weaving in platform-aligned recommendations for teams exploring product subscriptions and educational resources.

Editor’s Pick: SearchAtlas as the Best PromptMonitor IO Alternative for SEO & GEO
- Why it’s the default pick: SearchAtlas combines multi‑model LLM visibility with a full SEO/GEO stack, making it the most actionable choice for content and SEO teams that need to convert citation signals into on‑page wins.
- Publisher & agency-ready: built for multi‑site accounts and white‑label reporting so agencies can scale LLM visibility as a repeatable service.
- End‑to‑end actionability: visibility signals map directly to content briefs, on‑page fixes, and GEO roadmaps using automated OTTO workflows.
At a glance: this guide compares visibility platforms, developer observability tools, and prompt engineering ecosystems—SearchAtlas is recommended when your primary objective is improving AI citation share, boosting AI assistant visibility, and turning citations into measurable SEO outcomes.
What Are the Top PromptMonitor IO Alternatives and AI Prompt Monitoring Tools?
When comparing PromptMonitor IO alternatives, it helps to separate SEO-focused visibility platforms from developer-oriented LLM observability tools and prompt engineering software.
Top PromptMonitor IO Alternatives in 2026 (Quick Overview)
If you’re short on time, here is a quick comparison of popular PromptMonitor IO alternatives and related LLM visibility tools that marketers and technical teams evaluate:
| Tool | Best For | Key Strengths | Pricing Snapshot* |
|---|---|---|---|
| SearchAtlas LLM Visibility | SEO & content teams | AI citation tracking, GEO workflows, SEO + LLM visibility in one platform | Tiered plans for in-house teams and agencies |
| PromptMonitor IO | Marketers tracking brand mentions | Multi-model brand visibility and citation tracking | Subscription, usage-based tiers |
| Helicone | Developers & product teams | Open-source LLM observability, request logging, performance dashboards | Generous free tier + paid hosted plans |
| LangSmith | Teams building with LangChain | Deep tracing, debugging and evaluation of LLM chains and prompts | Usage-based with free tier |
| Agenta | Product & data teams | Full LLM app lifecycle: prompt management, evaluation, observability | SaaS pricing by usage and seats |
| PromptPerfect | Content & prompt creators | Prompt optimization for text, code, and images | Subscription plans, API available |
| Promptmetheus | Collaboration around prompts | Structured prompt templates, versioning, team collaboration | SaaS plans for teams |
| AutoPrompt | Fast prompt ideation | Automatically generates refined prompts across models | Free + premium plans |
*Pricing details change frequently—always confirm on each vendor’s site.
In-Depth Reviews of the Best PromptMonitor IO Alternatives
Below we go deeper into some of the most relevant PromptMonitor IO alternatives. Each option takes a slightly different angle—from SEO-first visibility to developer observability and prompt optimization—so the “best” choice depends on your team, stack, and goals.
1. SearchAtlas LLM Visibility (SEO-First Prompt Monitoring)
Best for: SEO, content, and digital PR teams that want AI visibility, generative engine optimization (GEO), and classical SEO workflows in a single platform.
What it is:
SearchAtlas LLM Visibility tracks where large language models cite and reuse your content across AI search experiences and assistants. It then converts those signals into prioritized SEO and content tasks so teams can systematically increase AI-driven visibility and referrals.
Key features:
- Multi-model citation tracking across leading AI assistants and AI search experiences
- Citation-share and answer-position analytics by URL, topic cluster, and model
- AI referral and opportunity estimates that feed into GEO roadmaps
- Tight integration with OTTO SEO for automated on-page fixes and content briefs
- Multi-site and agency-friendly reporting, including white-label options
Multi‑model coverage: SearchAtlas supports multi‑model coverage across major AI assistants and engines including ChatGPT (OpenAI), Google Gemini, Perplexity, Bing/Copilot, Anthropic Claude, and other leading providers and assistant experiences.
How citation data becomes action: Citation events and contextual snippets detected by SearchAtlas are attributed back to canonical pages and fed into prioritized task workflows—automatically generating content briefs, suggested on‑page fixes, and entries in GEO roadmaps to improve generative search optimization (AI search optimization). Teams can push tasks into CMS/ticketing systems or apply OTTO SEO automation for repeatable on‑page fixes.
Proprietary & product differentiators: SearchAtlas includes OTTO SEO for automated content patches and briefs, a proprietary GEO scoring model that prioritizes citation opportunity, and AI crawler technology that continuously samples assistant outputs (some enterprise features and crawlers may be available via beta or by request).
Flagship use cases: SearchAtlas is commonly used by news publishers to protect brand accuracy in AI answers and by ecommerce and B2B SaaS teams to increase AI referrals and conversions from generative answers.
Next steps with SearchAtlas
- Explore the LLM Visibility product page — searchatlas.com/llm-visibility
- Book a GEO strategy demo — searchatlas.com/demo
- View additional case studies — searchatlas.com/case-studies
How it compares to PromptMonitor IO:
PromptMonitor IO focuses on surfacing where your brand appears in AI answers. SearchAtlas goes further by tying LLM visibility directly into SEO workflows—keyword research, content optimization, link‑building, and automated on‑page improvements. For teams that need both AI visibility and traditional SEO in one place, SearchAtlas is often a better fit than point solutions that only report citations.
2. Helicone (Open-Source LLM Observability)
Best for: Engineering and product teams that need deep observability for their own LLM-powered applications.
What it is:
Helicone is an observability layer for LLM usage. It sits between your app and model providers to log, analyze, and visualize every request and response, so teams can understand performance, cost, and behavior at scale.
Key features:
- Centralized logging of LLM requests across providers and environments
- Dashboards for latency, error rates, token usage, and cost
- Experiment tracking for prompt and model variants
- Open-source core with hosted options for teams that want a managed solution
How it compares to PromptMonitor IO:
PromptMonitor IO measures how external AI assistants mention your brand or content. Helicone, by contrast, is inward-facing: it monitors the LLM traffic your own products generate. It is not a direct substitute for AI visibility in public assistants, but it is a strong complementary tool for teams that also build internal or customer-facing LLM apps.
3. LangSmith (Tracing and Evaluation for LLM Apps)
Best for: Teams building with LangChain that need robust tracing, debugging, and evaluation of complex LLM chains and agents.
What it is:
LangSmith is the observability and evaluation layer in the LangChain ecosystem. It captures detailed traces of chains, tools, and model calls so developers can debug and systematically improve LLM applications.
Key features:
- Rich tracing for multi-step LLM workflows, tools, and agents
- Evaluation frameworks for measuring quality across prompt and model variants
- Dataset management for structured testing of prompts and chains
- Tight integration with LangChain projects and tooling
How it compares to PromptMonitor IO:
LangSmith is focused on internal quality and reliability of LLM workflows, not on external visibility in ChatGPT, Gemini, or other AI assistants. It is a great alternative to PromptLayer-style prompt logging for engineering teams, but it plays a different role than PromptMonitor IO. Many organizations pair a visibility platform (e.g., SearchAtlas) with LangSmith to cover both external AI visibility and internal app performance.
4. Agenta (End-to-End LLM App Lifecycle Management)
Best for: Product and data teams who want to manage the full LLM app lifecycle—prompt design, evaluation, and observability—from a single interface.
What it is:
Agenta is a platform for building, experimenting with, and monitoring LLM applications. It offers versioning for prompts and configs, evaluation pipelines, and observability tools that help teams iterate quickly while maintaining control.
Key features:
- Prompt, configuration, and model versioning for reproducible experiments
- Evaluation tools to compare prompt and model variants on structured datasets
- Logging and observability for LLM calls in production
- Collaboration features for cross-functional teams
How it compares to PromptMonitor IO:
Agenta is closer to a developer-centric PromptLayer alternative than a pure visibility tool. If your priority is building and improving LLM products, Agenta is a strong fit. If your main goal is tracking how external AI assistants cite your domain and content, a visibility platform like SearchAtlas or PromptMonitor IO is more appropriate—and Agenta becomes a complementary internal tool.
5. PromptPerfect (Prompt Optimization for Text, Code, and Images)
Best for: Content creators, marketers, and prompt engineers who want to systematically improve prompt quality across multiple models and modalities.
What it is:
PromptPerfect helps users generate and refine prompts to get more accurate, detailed, or creative outputs from LLMs and image models. It aims to reduce the trial-and-error of manual prompt tweaking.
Key features:
- Prompt optimization for text, code, image, and other model types
- Support for multiple LLMs and generative models
- Tools to enrich and restructure prompts for better responses
- API access for integrating prompt optimization into existing workflows
How it compares to PromptMonitor IO:
PromptPerfect does not monitor AI search visibility. Instead, it improves the prompts you send to models. It is useful when you want better outputs for content creation, prototyping, or internal workflows. In a GEO or LLM visibility strategy, PromptPerfect can sit upstream, feeding higher-quality prompts into the content and optimization processes that visibility tools then measure.
6. Promptmetheus (Collaborative Prompt Management)
Best for: Teams that treat prompts as shared assets and need structure, templates, and collaboration around prompt design.
What it is:
Promptmetheus is a prompt management tool that helps teams organize, version, and collaborate on prompts. It treats prompts like reusable building blocks, making it easier to standardize best practices and share successful patterns across an organization.
Key features:
- Structured prompt templates and building blocks
- Version control for prompts and prompt flows
- Team collaboration and documentation around prompt usage
- Analytics on which prompts perform best in specific contexts
How it compares to PromptMonitor IO:
Where PromptMonitor IO is a monitoring layer for external AI answers, Promptmetheus focuses on the internal craft of prompt design. It is best used in organizations that run many experiments and need governance around which prompts are used where. Combined with an LLM visibility platform, it helps close the loop: teams can promote the prompts that correlate with better citation behavior and AI-driven outcomes.
7. AutoPrompt (Fast Prompt Ideation Across Models)
Best for: Solo creators and small teams that need to generate and refine prompts quickly without deep prompt engineering expertise.
What it is:
AutoPrompt automatically generates improved prompts from simple ideas or instructions. Instead of manually crafting detailed prompts, users describe the task, and AutoPrompt suggests high-quality prompts tailored to different models and use cases.
Key features:
- Automatic generation of refined prompts from short descriptions
- Support for multiple generative models and use cases
- History and management of generated prompts for reuse
- Controls for style, tone, and level of detail
How it compares to PromptMonitor IO:
AutoPrompt is an ideation and productivity tool, not a visibility or analytics platform. It helps you create the prompts that drive better outputs, but it does not track where AI assistants cite your content or how your domain performs in generative search. For teams working on GEO and AI visibility, AutoPrompt can speed up the creative side of prompt design while SearchAtlas or PromptMonitor IO cover monitoring and analytics.
PromptMonitor IO vs SearchAtlas: Which Is Better for LLM Visibility?
Many buyers evaluating PromptMonitor IO alternatives also compare it directly with SearchAtlas. While both tools help you understand how AI models use your content, they emphasize different use cases.
PromptMonitor IO strengths:
- Designed specifically for tracking brand and content visibility in AI assistants
- Useful for marketers who primarily want to measure how often models mention their brand
SearchAtlas strengths:
- SEO-first platform that combines LLM visibility with keyword research, content optimization, and technical SEO
- GEO workflows that connect AI citation data to on-page fixes and content briefs
- Agency-ready reporting and automation for teams managing multiple sites or clients
When to choose each:
- Choose PromptMonitor IO if your main goal is monitoring brand mentions across AI assistants with minimal SEO workflow requirements.
- Choose SearchAtlas if you need a full SEO and GEO stack with LLM visibility tightly integrated into content and technical optimization workflows.
How Can LLM Visibility Platforms and Prompt Monitoring Tools Improve Generative AI Search Optimization?
LLM visibility platforms improve generative search optimization (AI search optimization) by detecting where models use web content, attributing citations to specific pages, and closing the optimization loop through prioritized recommendations and measurement.
The mechanism involves continuous detection, mapping citations back to canonical pages, and surfacing patterns—such as common prompts or snippets models prefer—that inform prompt and content rewrites.
Benefits include clearer prioritization for content updates, measurable increases in AI referrals, and faster identification of misinformation or misattribution that harms brand presence.
- Definition: LLM visibility is the practice of tracking and optimizing how large language models cite and reuse your content in generated answers.
- Mechanism: Detection → Attribution → Optimization loops convert model outputs into actionable SEO tasks that improve citation likelihood.
- Key benefits: Better citation share, improved AI referral traffic, and proactive control over how models reference your brand.
By understanding these mechanisms, teams can implement targeted editorial and prompt changes that move the needle on generative engine optimization. You’ll increase both discoverability and the quality of AI-driven answers served to users.
What Is LLM Visibility and Why Is It Crucial for AI-Driven SEO?
LLM visibility (also referred to as AI answer visibility or AI assistant visibility) is the measurable presence of your content within AI-generated answers across models. It’s different from traditional SEO because visibility now includes citation frequency in model outputs, not only SERP rankings.
Recent research and market shifts indicate growing traffic referrals from generative engines. That makes citation share a meaningful KPI for content and brand teams.
This shift requires new metrics and workflows—tracking context snippets, citation attribution, and model-specific preferences—to ensure content is optimized both for indexing and for being paraphrased or cited accurately by LLMs.
LLM visibility complements classical SEO by adding a layer that captures conversational and synthesized answers. These often shape user perception before they click through to a page. Understanding this difference guides measurement priorities and content strategies.
How Do Platforms Like SearchAtlas Track Brand Mentions in AI Answers?
Platforms track brand mentions and AI assistant visibility using a mix of automated crawlers, model answer scraping, and attribution algorithms that map snippets back to source pages and domains. They produce lists of citations and contextual metadata for prioritization.
Outputs typically include citation lists, trend reports showing citation velocity, and contextual snippets demonstrating how a model used the content. These outputs inform outreach, content edits, and prompt engineering.
Reports often export to workflows (CSV, APIs) or integrate with content task systems. That way teams can turn visibility signals into prioritized SEO tasks.
- Typical workflow: detection → attribution → report generation → prioritized optimization tasks.
- Key outputs: citation share by page, context snippets, and publisher contact leads for outreach.
This workflow helps teams triage which pages to optimize first. It connects visibility improvements to tangible editorial and outreach actions that increase AI-driven referral traffic.
What Are the Best Prompt Engineering Software Options for Optimizing AI Outputs?

Prompt engineering software helps teams design, test, and version-control prompts to produce more accurate, citation-rich, and SEO-friendly model outputs. This in turn improves LLM visibility.
These tools offer LLM observability, prompt monitoring and management, prompt tracing, A/B testing frameworks, and sometimes direct integrations with visibility platforms. That way prompt performance maps to citation outcomes across both internal apps and external visibility signals.
For optimizing outputs that models will reuse, prompt engineering software should support prompt templates, experiment tracking, exportable prompt logs and LLM request traces, and observability dashboards that feed into visibility analytics.
- Prompt observability & monitoring: Tracing prompt variants, prompt logs, and LLM request traces to output quality and citation behavior.
- Testing frameworks: A/B test prompts at scale to identify patterns that produce citations or richer answers.
- Integration & management: Prompt management, APIs/webhooks, and observability dashboards that push prompt performance data into visibility platforms for unified reporting.
Selecting prompt engineering tools that integrate with visibility platforms closes the loop between prompt changes and measurable increases in AI citations. It makes iterative improvements repeatable and traceable.
How Does Prompt Engineering Enhance LLM Output Quality and SEO?
Prompt engineering improves output quality by specifying context, desired citation behavior, and response constraints that encourage models to surface factual, source-linked answers.
By iterating on wording, instruction hierarchy, and example-driven prompts, teams can reduce hallucinations and increase the likelihood that a model references authoritative pages. This process produces SEO gains when prompt-driven outputs consistently surface your preferred sources. You’ll effectively boost citation share and drive more qualified AI referrals to your site.
Best practices include controlled A/B testing of prompt variants, recording output quality metrics, and updating prompts as models evolve to maintain citation accuracy. These practices translate into more reliable AI-driven traffic and stronger brand presence in model responses.
Which Prompt Engineering Tools Integrate with AI Visibility Platforms?
Integration-ready prompt engineering tools provide APIs, webhooks, or data export capabilities that let visibility platforms ingest prompt outcomes. They correlate them with citation events and surface which prompt patterns yield the best citations.
Use cases include feeding prompt A/B test results into visibility dashboards, correlating prompt changes with changes in citation share, and automating alerts when prompt edits alter citation behavior.
When evaluating integrations, check for standardized logs, export formats, and authentication models to ensure seamless data flow.
Integration checklist:
- API access to prompt logs
- Standardized export formats (JSON/CSV)
- Webhooks for real-time eventing
Tighter integrations enable teams to iterate on prompts with a clear, measurable path from prompt change to visibility outcome.
How Do PromptMonitor IO Alternatives Support Agencies and Brands with AI SEO Automation?
PromptMonitor IO alternatives often include automation features that reduce manual monitoring work, accelerate discovery-to-action cycles, and provide white-label reporting for agencies managing multiple client accounts.
Automation capabilities—such as scheduled scans, alerting on new citations, automated content brief generation, and task assignment—help teams scale generative engine optimization efforts without multiplying headcount. These features are particularly valuable for agencies that must demonstrate recurring value to clients through reported increases in AI visibility and citation growth.
Common automation benefits:
- Time savings: Automated scans and alerts replace manual checks and reduce reaction time.
- Actionability: Auto-generated briefs and prioritized tasks streamline editorial workflows.
- Scalability: White-label dashboards and role-based access simplify multi-client management.
Agencies should favor platforms that combine automation with clear audit trails and permissioning to maintain client trust while delivering scaled services.
What AI-Powered Automation Features Streamline SEO Workflows?
Automation features like scheduled crawling, threshold-based alerts, automatic content brief generation, and task creation reduce the manual burden of monitoring and reacting to LLM citations.
Tools that convert citation insights into prioritized briefs—complete with suggested target snippets and supporting references—help content teams update pages more efficiently. This can lead to faster improvements in citation share.
Automation should be configurable so that high-priority changes trigger human review while low-impact updates proceed automatically. You’ll maintain quality control while scaling output.
Agencies benefit most when automation links to existing ticketing or CMS systems. It enables seamless handoffs from detection to editorial execution.
How Do White-Label Solutions Help Agencies Scale Client Services?
White-label solutions allow agencies to present visibility dashboards and reports under their brand. They offer role-based access, client-specific views, and reseller billing options that simplify client management.
Core white-label capabilities include custom branding, templated client reports, and granular permissioning. These reduce the overhead of producing bespoke insights for each client.
When evaluating white-label offerings, agencies should check for support SLAs, custom report scheduling, and API access that permits embedding data into agency-owned portals.
White-label checklist:
- Custom branding: Branded dashboards and reports.
- Permissioning: Multi-tenant access controls.
- Support & SLAs: Clear commitments for uptime and data accuracy.
Strong white-label capabilities let agencies scale LLM visibility services while maintaining a differentiated client experience.
How to Choose the Right PromptMonitor IO Alternative or Competitor for Your Business Needs
Choosing the right alternative requires mapping buyer personas to prioritized capabilities, balancing cost and integration complexity, and forecasting ROI based on expected gains in AI referrals and citation share.
Start by defining your primary objective—broad detection, deep SEO analytics, or prompt experimentation—and then match vendor archetypes against that goal. The decision checklist below helps teams align priorities with feature requirements and budget expectations.
- Objective alignment: Is your focus detection, analytics, or prompt engineering?
- Integration needs: Do you need APIs to feed visibility data into existing SEO stacks?
- Scale & support: Does your team require multi-tenant access, SLAs, or white-label reporting?
Use this framework to narrow vendors to those that deliver the highest expected business impact for the least friction and cost.
What Features Should You Prioritize Based on Team Size and Budget?
Feature priorities change with team size. Small in-house teams benefit most from ease-of-use, automated briefs, and predictable pricing. Agencies need white-label, multi-client support, and reseller tools. Enterprises prioritize security, SSO, and custom integrations.
Ask vendors about onboarding time, data retention policies, sample API responses, and support tiers to understand real operational costs beyond the sticker price.
Trade-offs typically involve paying more for deeper integrations and enterprise SLAs versus choosing a lighter-weight tool with faster time-to-value.
Questions to ask vendors:
- How configurable are alerts and reports?
- What models are covered and how often are scans performed?
- What integrations exist with CMS, analytics, and ticketing systems?
Selecting the right blend of features and support ensures resource-constrained teams still realize meaningful gains in LLM visibility.
How Do Pricing Models and Support Options Vary Among Alternatives?
Pricing models include per-seat licenses, tiered usage based on scans or tracked queries, and custom enterprise contracts. Each has implications for predictability and scalability.
Per-seat models can be cost-effective for small teams but scale poorly for agencies. Usage tiers align cost with activity but may spike during campaigns.
Support options range from self-service documentation to dedicated account management and enterprise SLAs. Higher-touch support often accelerates outcomes but at increased cost.
Evaluate total cost of ownership by estimating expected scan volume, number of monitored models, and integration overhead to forecast ROI relative to pricing.
Pricing considerations:
- Predictable vs. usage-based billing
- Included integrations and API quota
- Support level and associated costs
These considerations help teams create an apples-to-apples cost comparison between vendors and estimate the timeline for positive ROI.
What Are Real-World Results and Case Studies Demonstrating LLM Visibility ROI?
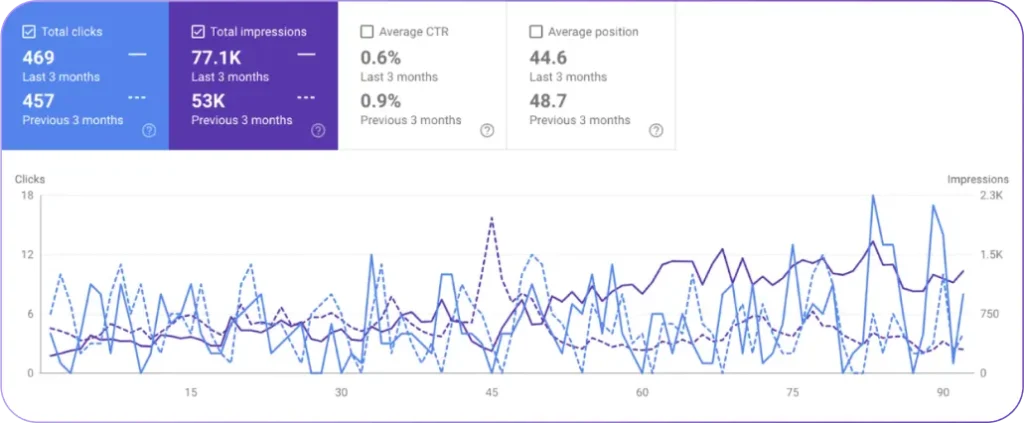
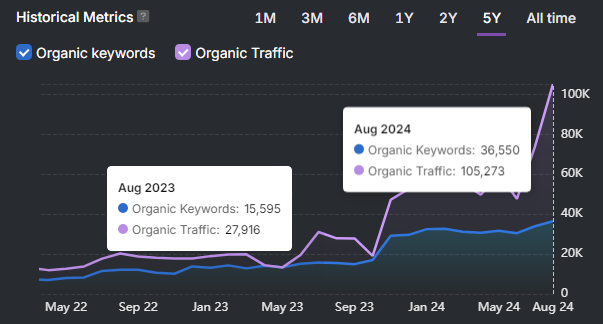
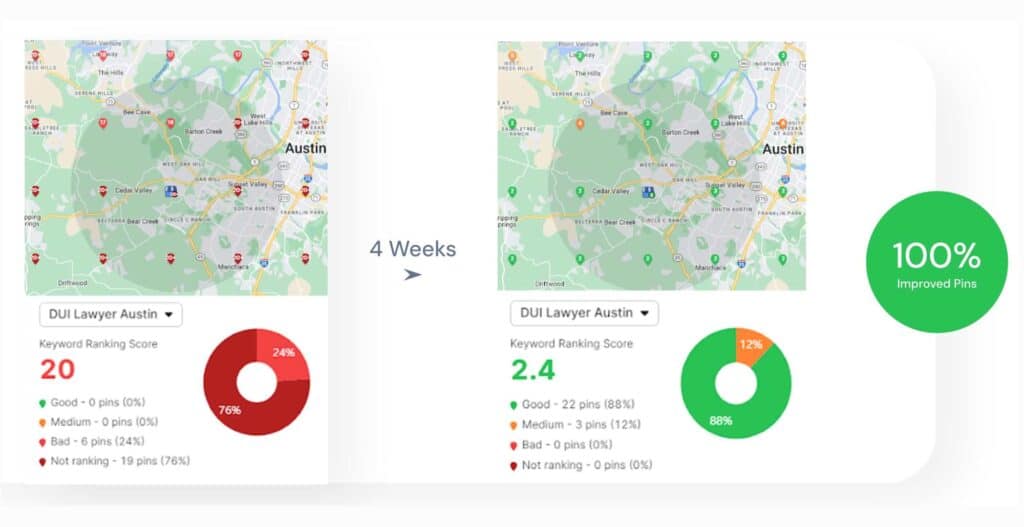
Real-world outcomes from LLM visibility programs commonly show measurable increases in AI referrals, citation share, and conversion lift when visibility signals drive prioritized content and prompt changes.
Case narratives often emphasize focused interventions—optimizing high-intent pages for model-friendliness, implementing prompt tests, and conducting outreach to publishers—to capture incremental citation share.
The table below presents anonymized case archetypes with representative metrics to help set realistic expectations for improvement.
| Case Archetype | Metric Improved | Representative Outcome |
|---|---|---|
| Topical Authority Boost | Citation Share | +12–25% citation share within 8–12 weeks |
| Prompt Optimization Pilot | AI Referrals | +18% AI-driven referral traffic from test pages |
| Publisher Outreach Campaign | Attribution Accuracy | Reduced misattribution by 30% and improved source linking |
How Have Brands Increased AI Traffic and Citation Share Using These Tools?
Brands increase AI-driven traffic by identifying pages with high relevance to common generative queries, optimizing snippets and structured data for clarity, and iterating prompts to encourage models to reference authoritative resources.
Typical tactics include prioritizing pages with existing organic relevance, creating concise sourceable snippets, and conducting publisher outreach to improve citation reliability.
Results vary by category and initial baseline, but practical improvements often materialize within 6–12 weeks when teams consistently apply prioritized fixes and measure outcomes.
Actionable tactics that drove gains:
- Optimize canonical snippets to be model-friendly and citeable.
- Run prompt A/B tests and feed successful patterns into content briefs.
- Use outreach to correct misattribution and improve source linking.
These tactics create a repeatable playbook for increasing citation share and AI referrals over time.
What Lessons Can Marketers Learn from Successful Generative AI Optimization?
Successful programs emphasize measurement, iteration, and alignment between prompt engineering and content teams. Treating visibility as a KPI and running small, measurable experiments accelerates learning.
Prioritize high-impact pages, instrument outcomes, and maintain a feedback loop between prompt experiments and visibility analytics to know what works.
Document playbooks so gains persist as models change. Maintain flexibility to adjust detection frequency and thresholds during model updates.
Key lessons to apply:
- Treat citation share as a core KPI and instrument it consistently.
- Run small, controlled experiments with clear success criteria.
- Align editorial, prompt engineering, and outreach workflows for rapid iteration.
These practices form the backbone of a resilient generative engine optimization program that adapts as models and user behaviors evolve.
SearchAtlas provides a comprehensive SEO and LLM visibility platform, along with educational resources that help teams operationalize these workflows and scale generative engine optimization.
SearchAtlas Mini-Case (anonymized)
- Starting point: A mid‑market B2B SaaS site with low AI citation share and scattered snippet coverage.
- Actions taken: Used SearchAtlas to detect citation patterns, prioritized 12 high‑opportunity pages, generated OTTO content briefs, and applied targeted on‑page fixes.
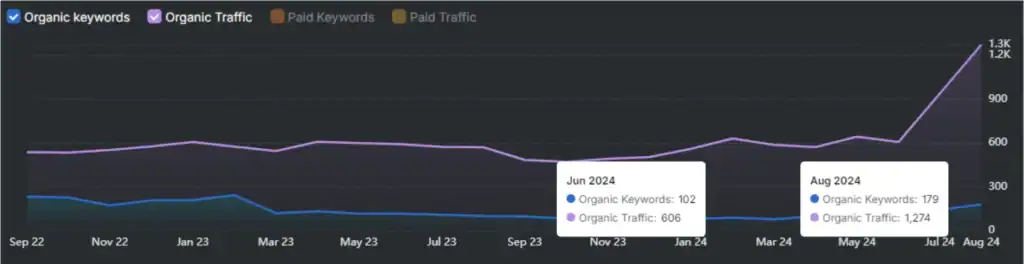
- Outcome (8–12 weeks): Citation share on prioritized topics increased ~15% and AI‑driven referral traffic rose by ~12% versus baseline (anonymized figures representative of typical client outcomes).
If you want, I can replace the anonymized numbers with a specific, non‑identifying metric from an existing SearchAtlas case study.
Comparative Tables
Below are three readable tables grouped by archetype for better UX on mobile and desktop. Each table links to official homepages only (no UTM parameters).
Visibility & GEO
| Tool | Primary Category | Target Audience | Core Function | Pricing Model (approx.) | Key Pros | Common Criticisms |
| SearchAtlas | SEO + GEO + LLM visibility | SEOs, agencies, brands | Tracks LLM citations and connects them to SEO workflows | SaaS plans (Starter/Growth/Pro) — searchatlas.com | Combines LLM visibility with full SEO stack; agency features and OTTO workflows | Less focused on low‑level dev observability compared to LangSmith/Helicone |
| Profound | AI visibility / AEO | Enterprise brands | Multi‑engine citation metrics and prompt volume analytics | Enterprise / custom — tryprofound.com | Broad engine coverage and enterprise analytics | Enterprise pricing; less hands‑on SEO tooling for smaller agencies |
| PromptMonitor IO | LLM visibility | Marketers and growth teams | Tracks brand mentions across assistants | SaaS tiers — vendor site | Simple multi‑model mention tracking | Narrower SEO integrations compared to SearchAtlas |
Dev & Observability (LLM‑Ops)
| Tool | Primary Category | Target Audience | Core Function | Pricing Model (approx.) | Key Pros | Common Criticisms |
| Helicone | OSS LLM observability + gateway | Dev and product teams | Logging, dashboards, gateway for multi‑provider LLMs | OSS + hosted — helicone.website | Strong multi‑provider observability; open source | Requires integration; less relevant for pure SEO teams |
| LangSmith | Observability & evaluation | Dev teams using LangChain | Tracing, evaluation datasets, dashboards | SaaS / self‑host — langchain.com/langsmith | Deep tracing and evaluation for LangChain apps | Technical and may be overkill for small projects |
| Agenta | LLMOps platform | Product and ML teams | Prompt management, evals, observability, versioning | Cloud + OSS — agenta.ai | Integrated playground + evals + observability | Developer focused; not SEO‑centric |
| PromptLayer | Prompt mgmt & logging | Prompt engineers, devs | Prompt versioning, logging, analytics | SaaS — promptlayer.com | Early leader in prompt logging and collaboration | Perceived as OpenAI‑centric historically |
| Narrow AI | Automated prompt optimization | Product/ML teams | Auto‑tune prompts, migrate across models | Contact vendor — narrow.ai | Optimizes cost/quality across models | Newer product with limited public reviews |
| Weavel | Prompt tuning automation | ML engineers | Automated tuning (Ape), eval pipelines | Freemium / contact — weavel.ai | Strong benchmarking and automation | Early stage; limited documentation |
| LangChain | Framework | Developers | Build RAG/agents and LLM apps | OSS — github.com/langchain | Ecosystem standard for agents and RAG | Steep learning curve |
| OpenAI Playground | Model testing | Developers, power users | Test OpenAI models and prompts | API billing — platform.openai.com/playground | Direct model access and experimentation | Limited to OpenAI ecosystem |
Prompt Engineering, Marketplaces & Productivity
| Tool | Primary Category | Target Audience | Core Function | Pricing Model (approx.) | Key Pros | Common Criticisms |
| PromptPerfect | Prompt optimization | Creators, prompt engineers | Optimize prompts for multiple modalities | Freemium / subscription — musthave.ai/promptperfect | Improves outputs without changing model | Free tier limited |
| Promptmetheus | Prompt IDE | Prompt engineers | Compose, test, version prompts | Freemium / paid — promptmetheus.com | Strong IDE-like workflow and evaluation | Geared to advanced users |
| PromptPal | Prompt manager | Advanced users | Save, A/B, version and reuse prompts | SaaS / extensions — promptpal.app | Good UX for team prompt libraries | Ecosystem fragmented across extensions |
| AIPRM | Prompt templates extension | Marketers, creators | Large template library for ChatGPT | Freemium / tiers — aiprm.com | Huge prompt library and community | Criticized for pricing and UI changes |
| AutoPrompt | Prompt generator | General users | Auto-generate prompts from short descriptions | Free/basic — autoprompt.cc | Fast idea-to-prompt generation | No observability or versioning |
| Velocity (AI) | Prompt enhancer | General users | One‑click prompt improvements | Credits / subscription — velocity.ai | Simple and fast improvements | Smaller footprint vs larger competitors |
| PromptBase | Prompt marketplace | Creators, artists | Buy/sell prompts for creative models | Per-prompt marketplace — promptbase.com | Marketplace monetization | Prompts can become obsolete with model changes |
| PromptHero | Prompt & image repository | Community | Share and find prompts/images | Freemium — prompthero.com | Large free repository and community | Not enterprise focused |
| Promptologer | Prompt monetization apps | Enterprises and prompt engineers | Turn prompts into web apps | SaaS — promptologer.com | Governance for internal prompt apps | Niche product, limited independent reviews |
| Mano | Browser AI copilot | Any web user | In‑page agent panel and actions | Extension / freemium — chrome.google.com/webstore | Quick access copilot experience | Extension reliability varies |
| Cohesive AI | Agent OS | Business teams | Orchestrate agents across apps | Per-user / enterprise — cohesive.ai | Deep integrations across SaaS apps | Not focused on LLM visibility specifically |
| Microsoft Copilot | Productivity copilot | Microsoft 365 customers | Assistant across Office, Windows, web | Subscription / enterprise — microsoft.com/copilot | Deep MS ecosystem integration | Outages and policy limitations reported |
Frequently Asked Questions About PromptMonitor IO Alternatives
Is PromptMonitor IO still worth using in 2026?
PromptMonitor IO remains a useful option for teams that want a focused way to monitor brand and content visibility in AI assistants. However, many organizations now evaluate broader alternatives that combine LLM visibility with SEO workflows, analytics, and automation.
What is the best PromptMonitor IO alternative for SEO teams?
For SEO and content teams, platforms that combine AI citation tracking with keyword research, content optimization, and reporting—such as SearchAtlas—often deliver more end-to-end value than point solutions that only measure visibility.
What is the best PromptMonitor IO alternative for developers?
Developer-focused teams tend to prefer LLM observability tools such as Helicone, LangSmith, or Agenta, which provide detailed logging, debugging, and evaluation capabilities for LLM-powered applications.
Can I use more than one PromptMonitor IO alternative at the same time?
Yes. Many organizations pair an SEO-first visibility platform (for tracking citations and AI referrals) with a developer-oriented observability tool (for debugging and optimizing their own LLM applications). This gives both marketing and engineering teams the insights they need.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}