

AI search results change because modern search systems generate answers dynamically rather than retrieve fixed rankings. Large language models synthesize responses at query time using probabilistic logic. Retrieval pipelines pull different sources per request. These properties create inherent response variability across identical prompts.
Underlying architectures rely on Retrieval-Augmented Generation, hybrid semantic retrieval, and chunk-level indexing. Web indexes update continuously, which shifts eligible source material. Freshness filters exclude outdated content before quality evaluation. Small corpus or ranking changes, therefore, propagate immediately into generated answers.
Citation drift amplifies this variability across platforms. Each AI engine applies distinct source preferences, retrievers, and rerankers. Probabilistic decoding introduces controlled randomness even under deterministic settings. Over time, citation overlap declines sharply compared to traditional organic search stability.
This variability alters SEO measurement, content strategy, and optimization priorities. Static rank tracking fails inside generative interfaces. Visibility depends on citation frequency, sentiment, and entity recognition. Effective strategies, therefore, focus on structured data, recency management, and Answer Engine Optimization.
What are AI Search Results?
AI Search Results are generative, answer-first outputs produced by AI-powered search systems that interpret intent, synthesize information, and deliver direct responses instead of ranked link lists. AI Search Results refer to experiences such as Google AI Overviews, ChatGPT with browsing, Perplexity, and similar systems that combine Large Language Models (LLMs), Natural Language Processing (NLP), and real-time retrieval. AI Search Results matter because they replace manual navigation with synthesized answers grounded in web indexes and knowledge bases.
What technical properties define AI Search Results? AI Search Results operate as nondeterministic, dynamically generated outputs that change for the same query based on data freshness, context, and model behavior. AI Search Results integrate multi-step reasoning, multimodality, and Retrieval-Augmented Generation (RAG), pairing generative text with links derived from organic indexes. Key properties include intent interpretation for complex queries, higher volatility than traditional rankings, and proactive personalization based on location, time, and interaction signals.
What functional characteristics distinguish AI Search Results from traditional search listings? AI Search Results emphasize synthesized overviews, conversational follow-ups, and zero-click discovery rather than static keyword matching. AI Search Results appear in dominant interface positions, often occupying over 67% of visible screen space, and include capabilities such as complex query handling, multimodal input processing, and native planning workflows. These characteristics reshape user behavior, traffic distribution, and optimization requirements across the search ecosystem.
What are the Key Reasons for Changing AI Search Results?

AI Search Results change because AI-powered search systems generate answers dynamically using live data, probabilistic models, and contextual signals rather than fixed rankings. These systems continuously adjust retrieval, synthesis, and citation selection based on data freshness, query interpretation, and model behavior, which causes visible variation across identical searches.
There are 5 key reasons for changing AI search results. The 5 key reasons for changing AI search results are listed below.
1. Dynamic Generation
Dynamic generation refers to the real-time probabilistic construction of answers by Large Language Models rather than the retrieval of fixed results, which matters because identical queries produce different outputs. AI search engines generate responses using probability distributions instead of static rankings, so wording, emphasis, and structure vary even when factual intent stays constant. This nondeterministic behavior makes result stability fundamentally different from traditional search.
How do Large Language Models introduce variability into AI search results? Large Language Models generate text by selecting the most likely next token based on mathematical probability, which causes natural variation across responses. The model does not store answers as fixed facts. The model recomputes responses at runtime using temperature, context weighting, and prompt framing, which alters phrasing and ordering even when the same information appears.
How does dynamic generation interact with Retrieval-Augmented Generation in AI search? Dynamic generation works with Retrieval-Augmented Generation by synthesizing retrieved content at query time, which increases variability across sessions. AI search engines pull different document chunks based on freshness, semantic scoring, and availability, then generate summaries from those inputs. Small shifts in retrieved material change which paragraphs, citations, or entities appear in the final answer.
How does chunk-level synthesis amplify result fluctuation in AI search? Dynamic generation operates on chunk-level retrieval rather than page-level ranking, which increases volatility in what content appears. A single paragraph outranks an entire page if it better satisfies the intent at that moment. This winner-takes-all selection causes frequent changes in visible answers even when the query remains unchanged.
2. Constant Data Updates
Constant data updates refer to the continuous ingestion, removal, and reprioritization of information across search indexes, live feeds, and internal data sources, which matters because AI search results rebuild answers from a moving data baseline. AI search systems no longer rely on fixed index refresh cycles; they integrate real-time pricing, inventory, policy changes, documents, and media, which alters what information is available at the moment a query runs.
How do constant data updates technically change AI search outputs? Constant data updates change AI search results because Retrieval-Augmented Generation reconstructs responses using whatever documents, chunks, and signals exist at query time. Index additions, content archival, freshness weighting, and hybrid keyword–vector retrieval shift relevance scores, which change which chunks the model selects, summarizes, and cites, even when the user query remains identical.
Why do constant data updates increase visible volatility for users and publishers? Constant data updates increase volatility because AI systems prioritize recency and live inputs over static authority, which reshapes answers continuously. Real-time citations, agentic retrieval, and continuous algorithmic updates cause wording, emphasis, sources, and rankings inside AI-generated responses to fluctuate far more frequently than traditional page-based search results.
3. High Volatility
High volatility refers to the rapid and frequent turnover of sources, citations, and wording in AI-generated answers, which matters because identical queries yield materially different results across runs. AI search engines operate on probabilistic architectures with intentional randomness, variable sampling parameters, and multi-stage inference pipelines, which makes fluctuation an inherent system behavior rather than an anomaly.
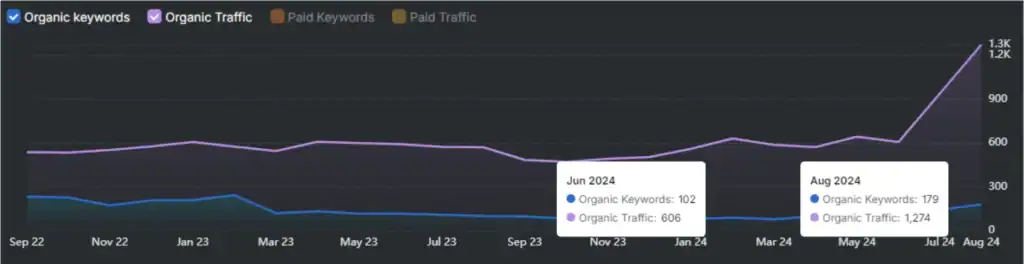
How is high volatility measured and observed across AI search platforms? High volatility appears in AI search results through citation drift, domain turnover, and low repeatability across consecutive queries. Empirical analysis shows 40%–60% of cited domains change every 30 days, with Google AI Overviews exceeding 59% drift and long-term volatility reaching 70%–90% over 6 months, far exceeding traditional organic ranking instability.
Why does high volatility affect visibility, trust, and optimization outcomes? High volatility affects AI search results because real-time retrieval, freshness prioritization, personalization signals, and evolving intent continuously reshape which sources surface. Query phrasing, geographic modifiers, live indexing, and competitor activity independently alter retrieval paths, causing AI results to change more frequently and more independently than traditional SEO rankings.
4. Context and Interpretation
Context and interpretation refer to how AI search engines infer meaning from language, intent, and situational signals, which matters because the same query implies different needs depending on user state and environment. AI search engines apply Natural Language Processing, entity recognition, and probabilistic reasoning to interpret what a user intends rather than what they literally type, which directly alters generated answers.
How do user intent and conversational context shape AI search results? Context and interpretation affect AI search results because systems carry intent across multi-turn conversations and adapt responses to descriptive, conversational queries. Query fan-out, predictive intent modeling, and conceptual linking allow AI search to connect symptoms to diagnoses or constraints to recommendations, causing outputs to change as the conversational context evolves.
How do personalization, real-time signals, and multimodality influence interpretation? Context and interpretation introduce variability because AI search engines factor in location, time, device state, personal data connections, and multimodal inputs. Real-time signals, visual understanding through tools like Google Lens, and agentic interpretation of tasks continuously reshape relevance scoring, leading AI search results to adjust dynamically for each user and moment.
5. Model Adjustments
Model adjustments refer to continuous changes in how AI search systems reason, retrieve, and generate answers, which matters because even small tuning decisions alter visibility, wording, and cited sources. AI search engines update ranking logic, inference pipelines, and generative behavior to improve accuracy, reduce hallucinations, and adapt to new usage patterns, which directly changes search outputs.
How do reasoning, retrieval, and generation updates affect AI search results? Model adjustments affect AI search results because systems evolve from simple retrieval toward deep, multi-step generative reasoning. Query fan-out, Deep Search, Retrieval-Augmented Generation prioritization, and semantic models such as BERT, MUM, and RankBrain change how intent is interpreted and which content chunks are selected, making responses dynamic rather than repeatable.
How do personalization, agentic features, and technical constraints amplify variability? Model adjustments introduce variability because AI search integrates personalization signals, agentic actions, and multimodal inputs while balancing compute limits and safety controls. Changes such as AI Mode rollout, agentic task execution, keywordless matching, and fine-tuning trade-offs cause AI search results to shift across users, queries, and time as models optimize performance, cost, and reliability.
How Does Retrieval-Augmented Generation Introduce Variability?
Retrieval-Augmented Generation (RAG) introduces variability because it constructs answers dynamically by combining probabilistic language model output with a changing set of retrieved documents. Each query triggers fresh retrieval decisions, so differences in embeddings, search algorithms, latency limits, or index state change determine which content chunks enter the model context and shape the final answer.
Why do retrieval mechanics and infrastructure choices amplify RAG variability? RAG variability increases because hybrid retrieval pipelines depend on vector search, reranking, and chunk selection that are sensitive to thresholds, timing, and noise. Differences in HNSW versus LSH indexing, retrieval triggers, latency guards, and chunking strategies alter relevance scores, causing different documents to be selected or omitted even when the prompt remains identical.
How do model behavior, data composition, and security risks affect RAG stability? RAG variability persists because model decoding settings, knowledge base composition, and adversarial exposure interact nonlinearly during generation. Temperature changes, Mixture of Experts routing, noisy or poisoned corpora, prompt injection within retrieved text, and embedding inaccuracies cascade through the pipeline, producing measurable citation drift, factual instability, and fluctuating answer structure across runs.
How Often Do Web Indexes Update and Affect AI Responses?
Web indexes update continuously, with daily signal changes, frequent incremental refreshes, and several broad core updates each year, which causes AI search responses to shift on a near-constant basis. Google applies thousands of small changes annually, runs rolling update cycles every few weeks, and deploys core updates quarterly, which means the underlying data feeding AI systems rarely remains static for more than a short period.
Why do index update cycles translate into visible AI response changes? AI search systems recalculate relevance whenever indexed content, freshness signals, or engagement data changes. AI Overviews react fastest because they pull directly from the live search index, while generative models such as ChatGPT reflect changes with a delay of weeks due to knowledge cutoffs and refresh cycles. Content updated within 30 to 90 days gains priority, while material older than 12 months faces immediate exclusion from AI summaries.
How do technical and economic constraints amplify update-driven volatility? Index updates affect AI responses unevenly because retrieval costs, latency limits, and indexing overhead restrict how much data systems process in real time. Parameter removals, database write bottlenecks, and crawl scheduling decisions alter visibility windows, contributing to rapid citation turnover, declining click-through rates, and measurable traffic erosion as AI-generated answers adapt to the latest indexed state.
What is Citation Drift in AI Search?
Citation Drift in AI Search refers to the measurable percentage of domains or sources that appear in an AI-generated response at one point in time but disappear or change when the same prompt is repeated later. Citation Drift matters because it breaks referential reproducibility, meaning identical questions no longer return stable sources, unlike traditional search results that change gradually. In AI systems, Citation Drift reflects rapid source rotation driven by probabilistic generation, live retrieval, and dynamic ranking rather than fixed indexing.
Why does citation drift occur, and why does it matter for brands and SEO? Citation Drift occurs because AI search systems combine probabilistic language models, Retrieval-Augmented Generation, vector embeddings, and chunk-level retrieval that continuously reshuffle eligible sources. Changes in terminology, content freshness, chunk structure, or third-party references cause entity amnesia, where a brand vanishes from AI summaries despite strong organic rankings. This volatility affects brand visibility, narrative framing, and trust, while remaining invisible to traditional SEO measurement tools that cannot track AI citation behavior.
How Does Citation Drift Compare Across Different AI Platforms?
Citation drift varies significantly by platform, with Google AI Overviews showing the highest volatility and Perplexity showing the lowest among major systems. Measured between June and July 2025, Google AI Overviews recorded a 59.3% citation drift, followed by ChatGPT at 54.1% and Microsoft Copilot at 53.4%, while Perplexity showed a comparatively lower but still substantial 40.5% drift. Across all platforms, 40–60% of cited domains change within a single month, and long-term drift increases to 70–90% over a six-month period, indicating that instability scales with time rather than query change.
Why do citation patterns differ so strongly between platforms? Citation drift differs because each AI platform relies on distinct retrieval stacks, source preferences, and freshness heuristics. ChatGPT aligns closely with the Bing index and heavily concentrates citations around established databases, with Wikipedia accounting for 47.9% of its top 10 sources. Perplexity favors real-time and user-generated content, citing Reddit heavily and rewarding pages updated within 30 days with 3.2x more citations. Google AI Overviews draws from the broader Google index with more diversified sourcing across Reddit, YouTube, LinkedIn, and Quora, which increases rotation but reduces single-source dominance.
How much consensus exists between platforms and traditional search results? Cross-platform consensus is extremely low, with only an 11% domain overlap between platforms like ChatGPT and Perplexity for identical prompts. Only 12% of URLs cited by AI systems overlap with Google’s top 10 organic results, and 88% of AI citations come from domains that do not rank on page 1 of traditional search. Perplexity shows the highest alignment with classic SEO at 33%, while other platforms operate largely independently, which explains why brand visibility and sentiment framing change dramatically across AI search engines even when the underlying facts remain the same.
Why is Citation Drift Higher in AI Search Than Traditional SEO Volatility?
Citation drift is higher in AI search because AI search engines generate probabilistic answers dynamically, whereas traditional SEO retrieves fixed rankings from a relatively stable index. AI search engines predict the most likely sequence of information using Large Language Models rather than returning a deterministic list of URLs. This probabilistic architecture introduces controlled randomness, meaning cited sources change even when the query, intent, and user remain constant. Traditional SEO volatility is constrained by four to five core updates per year, while AI systems reshuffle citations continuously.
How do architectural and retrieval differences amplify citation drift in AI search? AI citation drift increases because Retrieval-Augmented Generation, hybrid retrieval, and reranking layers introduce multiple variable decision points per query. A single prompt fans out into dozens of sub-queries, each retrieving different chunks of content through semantic and keyword matching. Minor phrasing changes, reranking thresholds, or competitor content updates alter which chunks enter the synthesis window, causing rapid source rotation that has no equivalent in page-level SEO ranking systems.
Why do recency bias and infrastructure incentives further separate AI drift from SEO volatility? AI platforms prioritize freshness, compute efficiency, and answer consolidation, which accelerates source turnover compared to traditional authority accumulation. Between 40% and 60% of cited domains change monthly, and drift expands to 70%–90% over six months, while traditional rankings often remain stable for years. AI systems favor recently updated content, frequently updated platforms like Wikipedia and Reddit, and server-rendered pages that reduce processing cost. As a result, AI visibility depends on ongoing probabilistic relevance rather than durable ranking position, making citation drift structurally higher than traditional SEO volatility.
How Frequently Do AI Platforms Update Their Models?
AI platforms update their models on a continuous basis, combining infrequent full retraining cycles with frequent fine-tuning, model edits, and real-time adjustments. Frontier providers such as OpenAI release major architectural upgrades every 1–2 years, while Google DeepMind iterates multiple Gemini variants several times per year. Across the industry, McKinsey reports that many generative AI providers now modify underlying systems weekly, which directly contributes to shifting outputs and inconsistent results over time.
What update methods drive this high update frequency? AI platforms rely on layered update methodologies rather than single replacement events. Full retraining occurs every few months to years due to extreme cost and computational demands, while fine-tuning runs more often to correct errors, improve safety, or adapt to new data distributions. High-frequency techniques such as model editing (ROME, MEMIT) allow individual facts to be updated in seconds, and declining inference costs, falling roughly 10x per year, enable faster deployment cycles.
Why do update frequencies vary by industry and use case? Update cadence depends on domain volatility, risk tolerance, and regulatory constraints. News, social analysis, and retail systems update daily to weekly, while finance updates weekly to monthly to counter fraud. Healthcare and legal models update from monthly to quarterly due to validation requirements. Fast-changing semantic domains require embedding updates every 3–6 months, whereas stable biomedical or legal corpora remain unchanged for 1–2 years.
How is model updating expected to evolve? AI platforms are shifting toward near-continuous and eventually automated update streams. Projections indicate movement from periodic cycles to hourly or real-time updates, managed increasingly by AI-driven deployment systems. This trajectory explains why AI search behavior changes far more frequently than traditional search and why model-driven variability is now a persistent characteristic rather than an exception.
Why Does AI Search Variability Matter for SEO and Content Strategy?
AI search variability matters because it breaks the assumption that rankings, traffic, and visibility are stable, making traditional SEO metrics insufficient. AI search operates on probabilistic, real-time generation rather than fixed rankings, which means citations, sources, and summaries change between identical queries within minutes. This volatility directly affects discoverability, attribution, and demand forecasting, because brands lose visibility without any change in organic rankings or site performance.
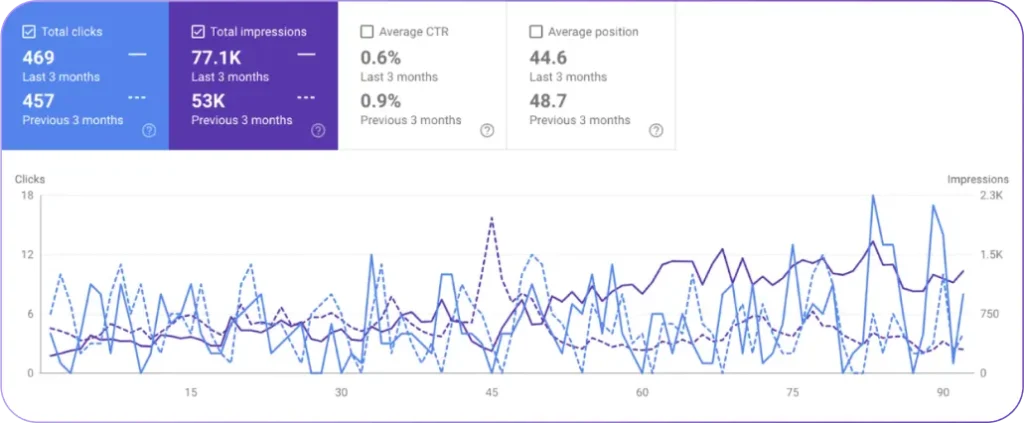
How does AI search variability change traffic and performance measurement? AI search variability shifts success metrics away from clicks and rankings toward visibility inside generated answers. AI Overviews and generative responses satisfy intent directly, which drives 15–45% traffic drops and 60% zero-click behavior. At the same time, referral traffic from large language model platforms remains limited at 2–3% of traditional Google traffic, creating a gap between perceived influence and measurable sessions. As a result, SEO strategies must track AI citation frequency, attribution rate, and consistency across runs instead of relying on position-based KPIs.
What strategic content changes does AI variability force? AI search variability forces content strategies to prioritize passage-level reuse, clarity, and contextual consistency over page-level optimization. AI systems retrieve and rerank individual content chunks, not entire pages, which means self-contained paragraphs, explicit answers, and structured headings determine visibility. Brands that engineer reusable information units, reinforce entities across multiple surfaces, and include multimodal assets outperform larger competitors that rely on authority alone. In this environment, SEO evolves from making content findable to making content extractable, repeatable, and resilient to generative reshuffling.
What Measurement Challenges Does Result Inconsistency Create?
Result inconsistency creates measurable obstacles that block reliable evaluation of AI search performance across time and platforms. These obstacles distort interpretation, weaken validation, and complicate strategic decisions that depend on stable signals. The challenges arise from statistical design, computational limits, data structure errors, and human judgment noise.
Some key measurement challenges created by result inconsistency are listed below.
- Lack of standardized metrics and definitions: No universal definition exists for inconsistency, volatility, or citation drift. Divergent terminology and reporting standards prevent stable baselines and block cross-platform comparison.
- Sensitivity to statistical methods and estimators: Inconsistency classification changes with metric choice, such as Odds Ratio versus Risk Difference. Estimator selection alone alters consistency outcomes for identical datasets.
- Heterogeneity masking true inconsistency: High variance across sources inflates uncertainty around effect sizes. This variance hides inconsistency signals or understates the magnitude during detection.
- Computational intractability at scale: Many inconsistency measures fall into coNP-hard or #coNP-complete classes. Exponential complexity blocks exact measurement for web-scale AI systems.
- Poor convergent and discriminant validity: Different inconsistency metrics show near-zero correlation. Several measures capture response bias or trait effects rather than system instability.
- Reliability gaps between measurement approaches: Likert-based metrics show low internal consistency. Frequency-based metrics show high reliability but remain structurally confounded.
- Data integrity and structural misalignment errors: Mismatched units, contradictory metadata, and incorrect temporal labels generate artificial inconsistency. These faults trigger quality control failures.
- Invisibility within standard analytics tools: Citation drift and off-SERP visibility loss escape traditional analytics systems. Detection requires manual testing or custom instrumentation.
- Human judgment and operational noise: Clerical error, fatigue, and incomplete information introduce uncontrolled variability. This noise contaminates expert-labeled and reviewed datasets.
- Misleading consistency thresholds: Fixed thresholds, such as 10%, misrepresent validity across contexts. Perfect consistency correlates poorly with correctness.
These challenges show that inconsistency resists treatment as a single volatility score. Accurate evaluation requires context-aware metrics, transparent methodology, and longitudinal survival-based analysis.
How Should Content Creators Adapt to Citation Volatility?
Content creators reduce citation volatility by restructuring content for passage-level retrieval and semantic precision. AI systems extract self-contained chunks rather than evaluate full pages or backlink profiles. Clear headings, short paragraphs, explicit entities, and list-based formatting increase retrieval probability within Retrieval-Augmented Generation systems.
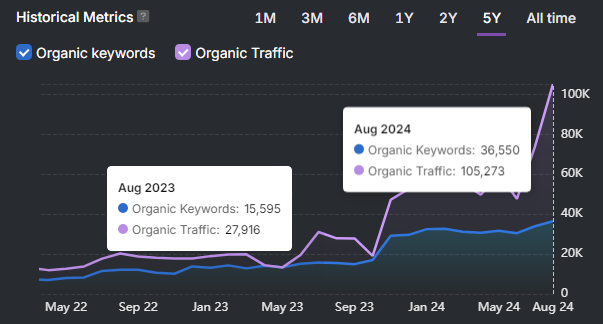
How does content freshness affect citation stability in AI search results? Content freshness directly controls citation stability within AI search systems. Pages updated within 90 days dominate AI citations, while static pages exit summaries without gradual decay. Empirical data shows 70% of cited pages received updates within six months, which links recency to citation survival.
How do content creators measure performance under high citation volatility? Content creators replace ranking-based tracking with citation-based measurement frameworks. Single-run observations fail under a 40% to 60% volatility floor, which requires repeated sampling. Citation frequency, source authority, and reappearance rates describe AI visibility more accurately than SERP positions.
What Technical Factors in RAG Architecture Cause Inconsistent Retrieval?
Technical factors inside the Retrieval Augmented Generation (RAG) architecture create inconsistent retrieval because each stage introduces independent failure modes. These failures compound across ingestion, embedding, retrieval, and orchestration layers. The result is variable context selection for identical queries.
Some key high-level technical factors in RAG architecture are listed below.
- Data ingestion and structural parsing failures: Retrieval breaks when systems misread document structure. OCR errors, layout complexity, and format incompatibility prevent correct text extraction. Missing tables, diagrams, or metadata removes essential context before retrieval begins.
- Chunking and segmentation misconfiguration: Inconsistent retrieval occurs when chunk size disrupts semantic coherence. Fixed-length chunking separates labels from values and fragments concepts. Semantic segmentation failure causes the retrieval of partial or misleading context.
- Embedding model and vector space misalignment: Similarity search fails when query embeddings and document embeddings differ. General-purpose models miss domain-specific meaning. High-dimensional vectors introduce latency and instability during nearest neighbor selection.
- Retrieval logic and ranking weaknesses: Naive top k retrieval introduces noise beyond relevance thresholds. Absence of re-ranking allows weak matches to dominate the context. Metric mismatches such as cosine versus L2 distort similarity scoring.
- Knowledge base decay and embedding rot: Retrieval stability drops after partial corpus changes without re-embedding. Stale indexes return outdated facts. Vector stores that resist incremental updates amplify inconsistency during refresh cycles.
- Orchestration and context window constraints: Asynchronous timing gaps cause generation without retrieved context. Large context windows reduce attention accuracy. Single-pass retrieval misses multi-step information dependencies.
- Metadata filtering and access control errors: Hard filters exclude relevant documents through misaligned tags. Access control failures block authorized data or expose restricted content. Governance drift alters retrieval scope across sessions.
These factors show that inconsistent retrieval originates from architectural interaction rather than isolated defects. Stable RAG performance requires aligned ingestion, embedding, retrieval, and orchestration logic. Measurement without architectural control remains unreliable.
How Do Platforms Balance Recency Versus Authority in Source Selection?
Platforms balance recency versus authority through a strict sequential evaluation, which prioritizes time validity before credibility scoring. Systems apply recency as a binary gate, which removes outdated sources before relevance or quality scoring occurs. This ordering prevents authoritative but stale information from entering downstream synthesis.
Why does recency override authority during initial evaluation? Recency overrides authority because time validity determines whether information qualifies for assessment. Evaluation pipelines exclude sources outside defined temporal windows, often from 3 to 5 years. This mechanism reduces exposure to outdated policies, pricing, or factual conditions.
How do platforms reintroduce authority after recency filtering? Platforms reintroduce authority through weighted relevance and quality scoring once recency thresholds pass. Sources receive relevance classifications that reflect scope similarity and magnitude alignment. Quality ratings then score execution accuracy, reliability, and outcome consistency.
How do platforms integrate recency and authority into final selection decisions? Platforms integrate recency and authority through composite confidence assessments rather than rank aggregation. Systems assign confidence tiers that reflect predictive reliability instead of numeric averages. Neutral ratings apply when recent authoritative data is absent, which prevents bias inflation.
Why does this balance reduce volatility in AI source selection? This balance reduces volatility because it constrains selection within time-valid and credibility-verified boundaries. Recency controls temporal drift, while authority stabilizes narrative trust. The interaction limits random source rotation without freezing outdated knowledge.
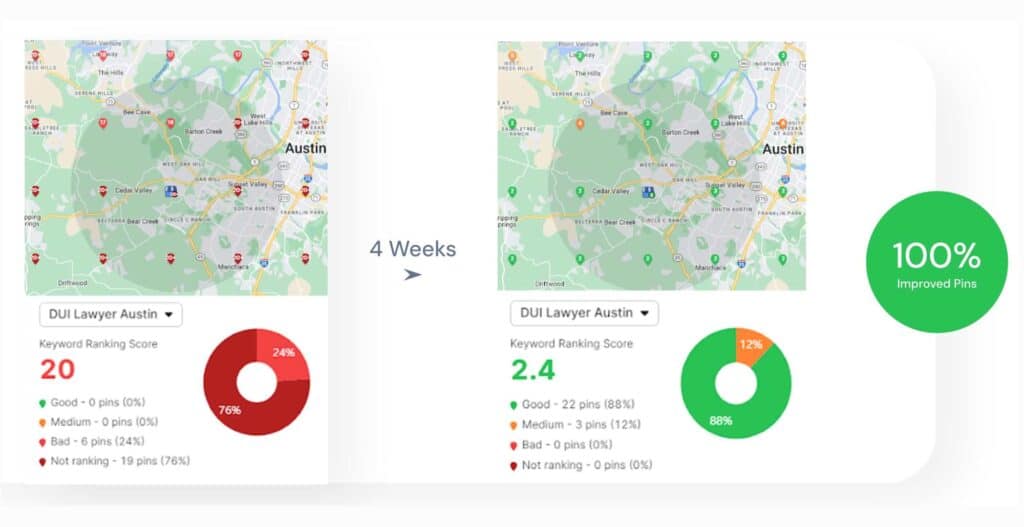
How Does Search Atlas Track AI Visibility Across Changing Results?
Search Atlas tracks AI visibility through continuous multi-platform data collection that records brand presence across generative search systems. The system ingests outputs from ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, and SearchGPT. APIs supply live data where access exists, while SERP simulation logs results where APIs remain unavailable.
What metrics does Search Atlas use to measure volatility and presence? Search Atlas quantifies visibility using citation share, share of voice, response positioning, and visibility score rankings. These metrics record brand mentions, citation frequency, and placement order within AI answers. Daily sampling captures rotation patterns that traditional rank tracking systems cannot observe.
How does the platform process and normalize changing AI outputs? Search Atlas processes data through automated ETL pipelines that standardize outputs across heterogeneous AI systems. Python workflows normalize prompts, responses, and citations before storage in analytics environments. Natural language processing classifies context and sentiment to prevent false attribution.
How does Search Atlas detect risk and competitive displacement? Search Atlas detects risk through sentiment tagging, competitor deltas, and threshold-based alerting. The system flags negative portrayals, factual inaccuracies, and sudden competitor dominance. Historical trendlines reveal persistence, decay, or recovery across repeated AI responses.
Why does this methodology remain stable under high citation volatility? The methodology remains stable because the measurement focuses on frequency and survival rather than single rankings. Aggregated sampling reduces noise created by probabilistic generation. This structure reflects how AI systems rotate sources across time and prompts.
What is Answer Engine Optimization (AEO)?
Answer Engine Optimization, abbreviated as AEO, is the practice of structuring content so AI systems select it as the cited answer. Answer Engine Optimization targets generative platforms such as ChatGPT, Gemini, Perplexity, and Google AI Overviews. Answer Engine Optimization shifts visibility from ranked links toward quoted responses inside AI-generated outputs.
Why does AEO exist as a distinct optimization discipline? AEO exists because AI systems generate a single synthesized answer rather than a ranked list of pages. Large language models evaluate context, authority, freshness, and structure instead of keyword density. This evaluation favors content that resolves one explicit question with verifiable evidence.
How does AEO differ from traditional search engine optimization? AEO differs from traditional SEO because success depends on citation frequency rather than page position. AI systems retrieve content at the passage level, which requires self-contained sections. Structured answers, explicit headings, and schema markup improve retrievability across probabilistic systems.
What signals determine success under AEO frameworks? AEO success depends on authority signals, structured formatting, and contextual alignment with user intent. Engines prioritize Experience, Expertise, Authoritativeness, and Trustworthiness signals. Fresh updates, consistent terminology, and third-party references stabilize citation selection across AI platforms.
How Does Trophy Content Perform in AI Search Systems?
Trophy content performs well in AI search systems when it matches narrow intent, structured formatting, and measurable attributes. AI systems favor trophy content that targets specific use cases, such as custom trophies or engraved glass awards. Passage-level retrieval rewards modular sections with factual specifications and clear entity definitions.
Why do AI systems differentiate between trophy content that appears and trophy content that wins selection? AI systems separate mention eligibility from recommendation eligibility through contextual precision. Broad trophy brands receive mentions without top selection, while niche trophy providers achieve higher win rates. Studies show brands with a narrow geographic or use case focus dominate AI recommendations despite limited traditional visibility.
What technical and behavioral factors increase trophy content visibility in AI-generated results? Structured HTML, schema markup, and behavioral trust signals increase trophy content citation frequency. FAQ schema increases AI appearances by 43%, while semantic HTML improves retrieval rates. AI systems prioritize measurable facts, stable availability signals, and engagement metrics over generalized brand claims.
What Structured Data Formats Improve Citation Consistency?
Structured data formats improve citation consistency by encoding entities, relationships, and metadata in machine-readable, deterministic schemas. AI systems parse structured formats faster, with fewer tokens, and with lower semantic ambiguity. Quantitative testing shows schema-based pages earn up to 3x higher citation likelihood.
Which core structured data formats demonstrate the highest citation stability across AI platforms? JSON-LD with Schema.org vocabulary delivers the highest citation consistency across AI search systems. Google identifies JSON-LD as the preferred implementation because it isolates data from presentation markup. Schema.org defines standardized entities such as Article, FAQPage, Product, Person, and Organization, which reduces entity misclassification during retrieval.
Which citation-specific formats strengthen reference reproducibility and verification accuracy? Citation formats such as CSL, CSL-JSON, BibTeX, RIS, Dublin Core, and CFF increase referential reproducibility. These formats enforce rigid field structures for authors, titles, dates, and identifiers. Studies report a 91.7% verification rate for structured citations compared with unstructured references.
Which technical infrastructure elements further stabilize citation selection in AI systems? Persistent identifiers and graph-based structures reduce citation drift at scale. DOIs, ISBNs, and ORCIDs anchor entities to authoritative registries such as Crossref. Graph RAG architectures combine structured triples with retrieval pipelines, which improves grounding and reduces source rotation.
How Often Should Content Be Refreshed for AI Visibility?
AI visibility depends on refresh cadence that aligns with model recency bias and retrieval prioritization. A 45-day baseline maintains stable citation probability across major AI platforms. Content updated within 90 days captures the majority of AI citations and bot interactions.
What refresh intervals maintain visibility across different AI systems and content types? Quarterly refresh cycles sustain rankings, while high-intent pages require monthly updates. Large Language Models prioritize content updated within 90 days, which accounts for 71% to 85% of citations. Industry velocity modifies cadence, where finance and news require weekly to monthly updates, while healthcare and education tolerate annual reviews.
Which signals trigger immediate refresh requirements for AI visibility preservation? Traffic decline, citation turnover, and AI Overview volatility indicate refresh urgency. A sustained 20% to 30% click decline over 4 to 8 weeks signals decay. Effective refreshes add new statistics, current examples, and machine-readable freshness markers, which shallow edits fail to satisfy.
Can Traditional SEO Ranking Tools Measure AI Search Performance?
No, traditional SEO ranking tools do not measure AI search performance accurately. Traditional tools track static URL positions, backlinks, and clicks, which AI systems do not use as primary outputs. AI engines generate synthesized answers, rotate citations, suppress clicks, and fragment visibility across multiple platforms.
Why do traditional SEO metrics fail inside AI-driven search environments? AI search replaces fixed rankings with probabilistic synthesis and citation rotation. Visibility depends on mention frequency, citation inclusion, sentiment framing, and response positioning. Zero-click behavior removes CTR as a reliable signal, while personalization invalidates position-based tracking.
What data and tooling are required to measure AI search performance reliably? Measurement requires multi-platform sampling, citation tracking, and sentiment analysis. Effective systems aggregate prompt-level responses across LLMs, analyze the share of voice, and track brand framing over time. API-first workflows and raw datasets replace dashboard-only ranking reports.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}