

Using Wikipedia to improve AI visibility of your brand means establishing a structured, neutral, and verifiable Wikipedia entity so Large Language Models (LLMs) and AI search engines retrieve, synthesize, and cite your brand inside generated answers. Optimizing Wikipedia for AI Visibility aligns brand information with encyclopedic standards, entity recognition, and structured data that AI systems prioritize during retrieval. Wikipedia functions as a high-trust data layer for AI systems, accounting for 27% of ChatGPT citations while representing less than 0.2% of raw training data, which shows deliberate oversampling by developers. Different AI engines reference content from Wikipedia because Wikipedia provides consistent definitions, infobox data, dates, and linked entities that integrate directly into knowledge graphs.
AI Visibility for brands refers to measurable inclusion inside AI-generated responses through mentions, citations, and narrative synthesis. Brand Presence on Wikipedia strengthens AI Visibility for Brands because AI search systems select sources based on entity clarity, semantic consistency, and cross-source validation. Google integrates Wikipedia into 89% of first-page results, and AI Overviews frequently reuse top-ranking sources, which creates a recursive visibility loop. This structural advantage influences how brands rank in DeepSeek AI, supports content optimization for DeepSeek, and increases Brand Visibility In DeepSeek when monitored with DeepSeek rank tracking tools.
Optimizing Wikipedia for AI Visibility supports Generative Engine Optimization (GEO) and Answer Engine Optimization (AEO) because both frameworks depend on structured definitions, factual stability, and citation eligibility. GEO governs how generative engines extract and summarize brand information, while AEO ensures content qualifies for answer-level inclusion. The advantage of using Wikipedia is authority amplification and durable AI citation, while the limitation is strict notability standards, neutral tone requirements, and low approval rates for new pages. Using Wikipedia strategically transforms brand documentation into a machine-readable authority asset that controls visibility across ChatGPT, Google AI Overviews, Gemini, Perplexity, and DeepSeek.

What is Wikipedia?
Wikipedia is a free online encyclopedia that serves as a multilingual, open-collaboration reference work hosted by the nonprofit Wikimedia Foundation. Wikipedia refers to a community-driven digital knowledge base where volunteer editors create, edit, and maintain articles under a neutral point of view policy and Creative Commons Attribution/Share-Alike 4.0 licensing. Jimmy Wales and Larry Sanger launched Wikipedia on January 15, 2001, to provide a free and collaborative alternative to traditional encyclopedias. Wikipedia has grown into the largest reference work in history and is ranked as the 6th most popular website globally as of March 2023.
What type of knowledge system does Wikipedia represent? Wikipedia represents a digital open-content repository that operates without a traditional expert-only editorial hierarchy. Wikipedia distinguishes itself from Encyclopædia Britannica and Scholarpedia through an “anyone can edit” model supported by structured governance. Wikipedia maintains over 66 million articles across 344 languages, and the English Wikipedia contains more than 7.1 million articles as of 2026. MediaWiki powers Wikipedia with version control, transparent edit history, and discussion pages that support dispute resolution and policy enforcement through the Five Pillars framework.
How does Wikipedia function at scale within the global information infrastructure? Wikipedia functions as a foundational knowledge layer for the internet and for artificial intelligence systems. Wikipedia attracts over 1.5 billion unique device visits monthly and reported 127 million users as of February 2024. A 2005 Nature study found an average of four inaccuracies per science entry compared to three in Britannica, which demonstrates competitive reliability under community governance. Large Language Models rely on the Wikipedia structured multilingual text for semantic learning, and 50% of physicians consult Wikipedia for health information, which positions Wikipedia as both a public reference system and a core training corpus for generative AI.
What is AI Visibility?
AI visibility is a digital marketing metric that measures the prominence, frequency, and contextual inclusion of a brand, product, or entity inside AI-generated responses. AI visibility refers to a binary and narrative inclusion model where an entity is either synthesized into the generated answer or excluded from it. The concept of AI visibility emerged in 2023 after the large-scale adoption of Large Language Models (LLMs) and the launch of Google AI Overviews, which shifted discovery from ranked links to synthesized answers. AI visibility evolved as a response to this shift, replacing blue-link ranking emphasis with answer-level presence measurement across ChatGPT, Perplexity, Gemini, Claude, and similar systems.
How does AI visibility differ from traditional search engine optimization (SEO)? AI visibility differs from traditional SEO because AI visibility measures answer inclusion rather than page position. Traditional SEO evaluates rankings, impressions, and clicks within search engine results pages (SERPs), while AI visibility evaluates mentions, citations, and narrative representation inside generated outputs. AI visibility aligns with Generative Engine Optimization (GEO) and Answer Engine Optimization (AEO), where authority depends on semantic clarity, entity consistency, and factual reliability instead of link authority alone. This distinction became critical as AI platforms like ChatGPT surpassed 100 million weekly users and AI Overviews began appearing in up to 30% of tracked searches.
What are the core components of AI visibility? The core components of AI visibility are mentions, citations, and trust transfer. Mentions refer to the explicit naming of a brand within AI-generated responses and appear in approximately 70% of non-technical AI queries. Citations refer to clickable source links embedded in generated answers and appear in 85% of Perplexity responses and 60% of Google AI Overviews. Trust transfer refers to the authority granted when an AI model recommends a brand as an objective solution, with 65% of users perceiving AI recommendations as more neutral than paid advertisements.
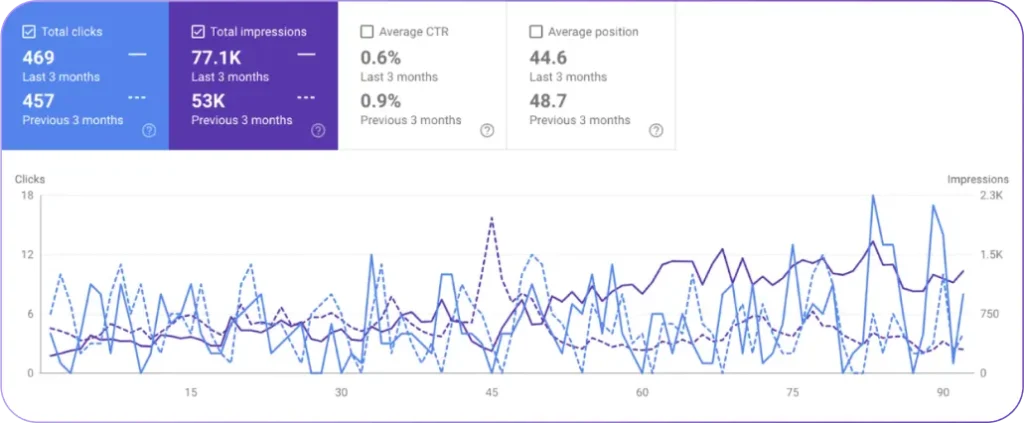
How is AI visibility measured and operationalized? AI visibility is measured through prompt-based tracking, sentiment analysis, and share-of-voice benchmarking across AI systems. Monitoring frameworks track up to 1,200 custom prompts daily to measure entity inclusion across different LLM environments. Visibility scoring incorporates sentiment classification because negative AI portrayals are 40% more damaging than invisibility. AI visibility functions as a performance indicator alongside Share-of-Voice (SOV) and organic search metrics, and 60% of CMOs plan to integrate AI visibility into dashboards by 2025 as AI-powered discovery replaces traditional engines.
How Does Wikipedia Improve AI Visibility?
Wikipedia improves AI visibility by functioning as a high-trust, structured entity source that artificial intelligence systems retrieve, validate, and cite during answer generation. Wikipedia accounts for 27% of ChatGPT citations and influences 89% of Google first-page results, which positions Wikipedia as a primary data layer for generative systems. Although Wikipedia represents less than 0.2% of raw training data, developers deliberately oversample Wikipedia because of its structured neutrality and verifiable sourcing. This structural dominance explains why search engine optimization wiki strategies increasingly intersect with Generative Engine Optimization (GEO), where visibility depends on citation eligibility instead of ranking position alone.
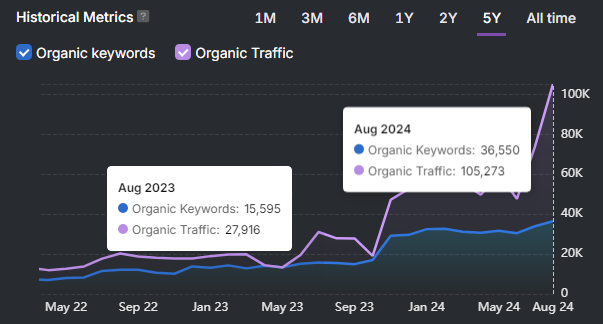
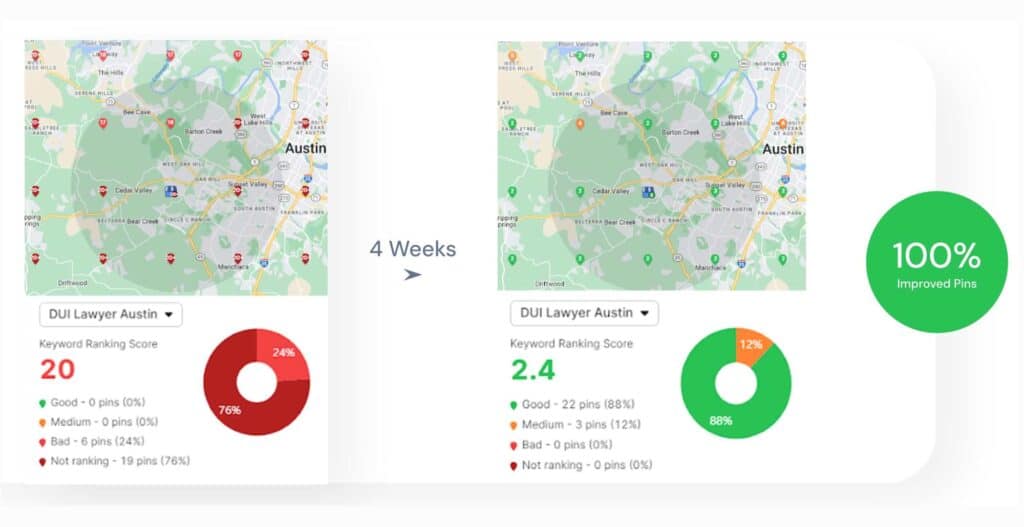
How does Wikipedia influence AI visibility and brand authority? Wikipedia increases AI visibility and brand authority through entity-based validation signals that correlate 3x stronger with AI inclusion than traditional search engine optimization methods. Companies with an established Wikipedia presence achieve up to 7x higher AI visibility compared to companies without one. The fintech company Ramp improved sector visibility from 19th to 8th position within 1 month and gained over 300 AI citations after optimizing its Wikipedia strategy. Wikipedia strengthens entity recognition, which improves inclusion across ChatGPT, Google AI Overviews, Gemini, Perplexity, and DeepSeek.
What structural elements of Wikipedia optimize AI data ingestion? Infoboxes, lead paragraphs, and hierarchical heading structures enable AI systems to parse and extract information with high accuracy. Infoboxes feed directly into knowledge graphs used by AI search engines. The first 1 to 4 lead paragraphs serve as primary summarization zones during retrieval-augmented generation. Hierarchical H1, H2, and H3 tags create machine-readable segmentation that increases extraction precision. These structural features make Wikipedia uniquely compatible with GEO frameworks because generative engines prioritize structured, entity-rich content.
What are the barriers and maintenance requirements for Wikipedia-based AI visibility? Wikipedia-based AI visibility requires strict notability compliance, neutral tone, and ongoing monitoring to maintain data integrity. Page approval requires 3 to 5 independent secondary sources, and only 25% of submissions receive approval, with 60% rejected for promotional tone or inadequate sourcing. The review backlog of over 2,800 submissions creates a 3 to 6 month delay, and ROI typically materializes within 6 to 18 months after publication. Weekly monitoring prevents vandalism from propagating incorrect data into AI models, and consistent sourcing preserves eligibility for AI citation. Wikipedia data quality prevents AI model degradation by providing a multilingual, human-curated corpus that reduces hallucination risk and supports long-term AI reliability.
Why Wikipedia Matters for AI Search Visibility?
Wikipedia matters for AI search visibility because Wikipedia functions as the foundational data layer that Large Language Models (LLMs) retrieve, validate, and reuse when generating answers. Wikipedia provides core training data for major models and supports Retrieval-Augmented Generation (RAG) systems such as REALM and DPR, which reduce hallucinations and improve factual grounding. Google maintains updated Knowledge Graph integrations through direct Wikimedia data feeds, and structured Wikipedia content converts into machine-readable knowledge graphs via Wikidata and DBpedia. This infrastructure position makes Wikipedia central to AI search visibility rather than supplementary to traditional search engine optimization.
How does Wikipedia influence search visibility and AI dominance? Wikipedia influences AI dominance by consistently ranking among the top global websites while serving as a primary citation source for ChatGPT, Claude, Gemini, and Perplexity. Wikipedia dominates search results for a broad range of entity-based queries, which creates a reinforcing loop between traditional search visibility and AI-generated answers. AI systems extract brand history, product details, and executive information directly from Wikipedia entries. This dominance produces an echo effect where AI summaries are amplified by journalists, analysts, and investors, which extends brand authority beyond the AI interface.
What technical advantages make Wikipedia critical for machine learning systems? Wikipedia provides machine-readable structure, multilingual coverage, and citation-backed authority that optimize model training and retrieval. Wikipedia uses heavy markup, cross-linking, standardized headings, and mandatory citations that improve parsing accuracy. Wikipedia operates in over 300 languages, which enables global entity alignment across multilingual queries. These structural characteristics cause AI systems to treat Wikipedia as a high-confidence reference corpus that influences internal model memory and citation behavior.
What strategic risks and brand impacts arise from Wikipedia dominance in AI systems? Wikipedia dominance introduces visibility leverage and creates reputational risk. Inaccurate or biased Wikipedia content propagates through AI-generated answers, creating a self-reinforcing misinformation loop. Brands without developed Wikipedia pages face competitive gaps because AI systems prioritize documented entities. Outdated or inconsistent multilingual entries persist inside LLM outputs even after corrections in one language edition. All edits remain publicly logged, which requires strict conflict-of-interest disclosure and continuous monitoring to maintain AI-aligned accuracy.
How is AI-first search changing Wikipedia’s strategic role? AI-first search transforms Wikipedia from a high-ranking website into the encyclopedia of record that shapes generative model memory. As users increasingly query ChatGPT, Gemini, Claude, and Perplexity instead of traditional search engines, visibility shifts from ranking to retrievability. Generative Engine Optimization (GEO) and AI Visibility Optimization frameworks focus on ensuring content remains citable and retrievable across LLMs. Wikipedia functions as the central node in this transition because AI systems prioritize Wikipedia entities when constructing direct answers, which elevates Wikipedia from search asset to AI infrastructure.
What are the AI Responses For Brands Before vs After Creating Wikipedia Page?
AI-generated responses for brands change significantly after a verified Wikipedia page establishes structured entity recognition and citation eligibility. The table below demonstrates how AI systems shift from fragmented, low-confidence summaries to structured, citation-backed answers once Brand Presence on Wikipedia is established.
| Prompt By User | Before Wikipedia Page | After Wikipedia Page |
|---|---|---|
| What is [Brand] and what does it do? | AI provides a vague summary based on scattered web mentions, startup directories, or third-party blogs. No citation or inconsistent attribution appears. | AI provides a structured definition sourced from Wikipedia, including founding date, industry classification, headquarters, and core offerings, often with citation. |
| Is [Brand] a trusted company? | AI responds cautiously due to limited authoritative signals. Information relies on reviews or secondary mentions. | AI references Wikipedia entity status, historical data, leadership, and verified milestones, which increases perceived credibility and trust transfer. |
| Who founded [Brand]? | AI returns incomplete or conflicting founder information pulled from press releases or scraped directories. | AI extracts founder data directly from Wikipedia infobox and lead paragraph, delivering consistent, citation-backed attribution. |
| What industry does [Brand] compete in? | AI infers industry context through keyword association without structured classification. | AI retrieves standardized industry classification from Wikipedia infobox and linked entities, improving semantic precision. |
| Is [Brand] comparable to competitors? | AI mentions competitors unevenly due to lack of entity authority signals. | AI references [Brand] alongside competitors that have Wikipedia pages, increasing inclusion frequency and Share of Voice in AI responses. |
The transition from no Wikipedia page to an approved Wikipedia entity shifts AI visibility from probabilistic inference to structured authority retrieval. Before page creation, AI systems rely on fragmented web signals that limit citation probability. After page approval, AI systems retrieve structured infobox data, lead paragraph definitions, and linked entities, which increase citation frequency, entity confidence, and inclusion across ChatGPT, Google AI Overviews, Gemini, Perplexity, and DeepSeek.
How To Use Wikipedia To Boost AI Search Visibility?
Using Wikipedia to boost AI search visibility requires structured entity development, neutral documentation, and knowledge graph alignment so AI systems retrieve and cite your brand inside generated answers. Wikipedia SEO strategies operate at the entity level, not the backlink level. Wikipedia for SEO improves eligibility for inclusion across ChatGPT, Google AI Overviews, Gemini, Perplexity, and DeepSeek because generative engines prioritize structured definitions and verified references.
The 11 steps above explain how to use Wikipedia to boost AI search visibility.
1. Audit Your Existing Pages Or Build A New One
Auditing existing pages or building a new one boosts AI search visibility because Wikipedia functions as a primary trust and entity-validation layer for Large Language Models (LLMs). AI systems weigh Wikipedia heavily in retrieval-augmented generation workflows, and brands without a compliant page risk exclusion from AI-generated answers. An audit identifies citation gaps, neutrality violations, outdated data, and structural weaknesses that reduce retrievability. Building a new compliant page establishes an indexed entity anchor that improves inclusion probability across ChatGPT, Gemini, Perplexity, Google AI Overviews, and DeepSeek.
How does Wikipedia trust status influence AI visibility? Wikipedia acts as a high-confidence validation source for AI engines. LLMs prioritize Wikipedia because it provides structured neutrality and verifiable sourcing. When a brand lacks a Wikipedia entity, AI engines default to competitors with established entries, which reduces share of voice in AI responses.
How do citations and recency affect AI inclusion? High-quality independent citations function as validation signals that LLMs use to confirm legitimacy. AI systems evaluate references and prefer recently updated pages over stale entries. Pages last updated years ago lose prominence, while refreshed entries increase citation probability in generated answers.
How does auditing reduce strategic risk? Auditing ensures compliance with General Notability Guidelines (WP:GNG) and Conflict of Interest policies, which protects long-term visibility. Page deletion or community challenge removes the primary AI data source entirely. Compliance stabilizes the entity as a durable AI retrieval node.
2. Create Structured, Neutral Content
Structured neutral content improves AI search visibility because machine-readable formatting and neutrality increase retrieval accuracy and trust scoring. LLMs prioritize clearly segmented sections, citation-backed statements, and objective definitions during summarization.
How does structure improve machine readability? Standardized formatting enables AI systems to extract entity definitions, attributes, and relationships with precision. Wikipedia introductions, headings, and references create predictable parsing zones that retrieval systems prioritize during response generation.
Why is neutrality a critical AI trust signal? Neutral tone signals third-party validation rather than self-promotion. AI systems deprioritize promotional language because authority scoring favors encyclopedic sources with consistent editorial governance.
How do structured citations enhance retrievability? LLMs evaluate footnotes to confirm cross-source agreement before inclusion. Independent news outlets and academic journals strengthen citation confidence, which increases answer-level visibility.
3. Use Infoboxes for Knowledge Graphs
Infoboxes improve AI visibility because they provide structured entity attributes that feed directly into knowledge graphs. AI engines extract founding dates, headquarters, industry classifications, and leadership data from infobox fields during entity resolution.
How does structured data influence AI systems? Knowledge graphs scale through structured triples, not prose paragraphs. Infobox attributes convert into machine-readable facts that power instant answers, featured panels, and voice responses.
Why does entity structure improve response accuracy? AI assistants reference infobox summaries when generating concise factual answers. Clear structured data reduces misinterpretation and increases citation likelihood across conversational systems.
4. Use Wikidata
Wikidata strengthens AI visibility by providing machine-queryable entity properties that power knowledge graphs and AI retrieval systems. Google Knowledge Graph and other AI engines source structured data from Wikidata to populate entity cards and carousels.
How does Wikidata impact visibility positioning? Knowledge Graph placements appear above organic results and influence perceived authority. Structured Wikidata entries increase eligibility for these high-visibility panels.
How does structured querying enhance AI retrieval? Vector database integration and semantic search allow LLMs to interpret meaning instead of matching keywords. Wikidata triples provide entity–attribute–value relationships that reduce hallucination risk and increase grounding.
Why is multilingual alignment important? Canonical identifiers ensure consistent entity recognition across languages. A single Q-ID anchors brand identity globally, which preserves discoverability in multilingual AI environments.
5. Optimize the Lead Paragraph
Optimizing the lead paragraph increases AI search visibility because LLMs prioritize the first 1 to 4 paragraphs during summarization and citation extraction. Wikipedia accounts for 27% of ChatGPT citations, and AI systems frequently extract definitions directly from the lead.
Why does the first sentence matter? The first sentence establishes the entity definition that anchors AI interpretation. Clear subject–verb–object structure improves parsing and strengthens entity resolution signals.
Why does front-loading factual data improve inclusion? AI engines preferentially cite content that presents key facts early. Founding year, industry classification, and geographic location increase retrieval precision and knowledge graph compatibility.

How does lead optimization amplify visibility? A structured lead combined with an infobox integrates directly into AI knowledge graphs. This integration increases citation frequency and produces measurable visibility gains across generative systems.
6. Establish Notability With Strong References
Notability establishes eligibility for long-term AI citation because Wikipedia pages require independent, significant coverage. Wikipedia contributes 27% of ChatGPT citations and influences 89% of first-page search results, which amplifies entities that meet notability thresholds.
How do independent sources strengthen AI authority? LLMs prioritize entities supported by multiple reliable publications. Independent coverage demonstrates sustained relevance, which increases AI inclusion probability.
Why does notability create competitive advantage? Entities that meet General Notability Guidelines gain structured presence inside the AI training and retrieval pipeline. Brands without compliant coverage remain excluded from authoritative AI outputs.
7. Use Third-Party Citations
Third-party citations increase AI visibility because generative systems validate facts through cross-source agreement. AI engines compare references during retrieval before selecting information for answer synthesis.
Why does citation diversity matter? Multiple independent domains strengthen entity reliability signals. Citation diversity increases confidence thresholds for inclusion in AI-generated responses.
Why does citation quality influence AI outcomes? High-authority publications function as validation anchors within LLM retrieval systems. Strong references increase citation frequency across conversational AI platforms.
8. Build A Wikipedia Cluster
A Wikipedia cluster improves AI visibility by creating interconnected entity pages that expand semantic footprint. Linked pages for founders, products, and technologies provide multiple retrieval entry points for LLMs.
How does clustering improve retrievability? Interlinked entities strengthen semantic mapping inside knowledge graphs. AI systems interpret clusters as higher-confidence entity ecosystems.
Why does multilingual clustering matter? Clustered entities across languages increase global AI discoverability. Multilingual consistency reinforces entity stability across international AI queries.
9. Maintain Transparency
Transparency protects AI visibility because stable, traceable edit histories reinforce data integrity for retrieval-augmented generation systems. Wikipedia public logs allow AI crawlers to distinguish between verified facts and unstable edits.
Why do COI disclosures matter? Undisclosed conflicts risk page deletion or credibility loss. Removal eliminates the primary AI entity source entirely.
How does open review strengthen AI reliability? Community moderation increases downstream data accuracy for knowledge graphs. AI systems prioritize sources with visible governance and accountability.
10. Focus on Entity Linking
Entity linking improves AI visibility by mapping surface terms to canonical identifiers that prevent ambiguity. Wikidata Q-IDs anchor brand identity within millions of structured relationships.
How does disambiguation improve retrieval? Entity resolution eliminates false matches between similarly named entities. AI systems retrieve the correct subject with higher precision.
Why do canonical IDs matter for AI reasoning? Persistent identifiers allow AI systems to anchor reasoning chains in structured knowledge bases. This grounding increases citation probability in complex generative answers.
11. Monitor and Update Content Regularly
Regular monitoring sustains AI visibility because LLMs prioritize freshness, citation validity, and structural accuracy. Updated entries receive higher trust weighting than stagnant pages.
How does recency influence AI ranking? Recent updates signal relevance and reliability to generative systems. Visibility spikes often occur after documented updates tied to verifiable events.
Why does maintenance preserve authority? Broken citations, outdated data, or vandalism reduce AI trust signals immediately. Continuous updates protect entity stability across AI search platforms.
Can You Directly Create A Wikipedia Page?
No, do not directly create your own Wikipedia page because direct self-editing violates Wikipedia conflict-of-interest and neutrality policies. Wikipedia operates under strict editorial governance that requires independent sourcing, neutral tone, and community review. Pages created or heavily edited by subjects without disclosure risk rejection, deletion, or permanent removal from the platform.
Why is direct editing discouraged? Direct editing creates bias risk and increases the probability of page rejection under the General Notability Guideline (WP:GNG) and Conflict of Interest (COI) rules. Wikipedia requires 3 to 5 independent secondary sources such as major news outlets or academic publications. Approximately 60% of rejected submissions fail due to promotional tone, and only about 25% of new submissions receive approval. Direct brand-created pages often trigger editorial scrutiny and deletion discussions.
What is the correct way to create a Wikipedia page? The correct method is to use the Articles for Creation (AfC) process instead of publishing directly. The Articles for Creation process routes the draft through volunteer review before publication. Contributors must draft the page in a sandbox, disclose any paid relationship, provide independent citations, and submit for review. This process reduces deletion risk, ensures policy compliance, and establishes a stable entity foundation that supports long-term AI visibility across generative search systems.
How To Create A Wikipedia Page?
Creating a Wikipedia page requires verified notability, structured drafting, community review, and policy compliance before publication in the Main namespace. Wikipedia enforces strict editorial, technical, and sourcing standards to prevent promotional or non-notable content.
The 6 structured steps below explain how to create a Wikipedia page correctly using the Articles for Creation process instead of direct publication.
- Create and age a registered account. Wikipedia requires a logged-in account for article creation outside Talk pages. Accounts must typically be at least 4 days old and have 10 edits to gain autoconfirmed status. This requirement reduces spam and promotional publishing risk.
- Confirm notability with independent secondary sources. Wikipedia requires significant coverage in reliable, independent, secondary sources such as major newspapers, academic journals, or reputable books. At least 3 strong references need to exist before drafting begins. Press releases, self-published blogs, and routine announcements do not qualify.
- Draft the article in Draftspace or via the Article Wizard. Use the Article Wizard if you are a beginner. Draft the article in Draftspace or a Sandbox to avoid immediate deletion. Maintain a neutral tone, summarize sources in your own words, and include inline citations for every factual claim. Wikipedia prohibits AI-generated content and promotional writing.
- Structure the article according to encyclopedic standards. Begin with a clear lead paragraph defining the subject. Add properly formatted sections such as History, Products, or Operations where relevant. Include citations using Wikipedia referencing format. Add appropriate categories and, if applicable, a correctly formatted infobox.
- Submit the draft using the Articles for Creation process. Add the {{subst:submit}} template to request review. Volunteer editors evaluate compliance with the General Notability Guideline and neutrality policies. Review timelines often take several weeks due to submission volume.
- Move to the Main space and monitor the page after approval. Once approved, the article moves to the Main namespace. Search engine indexing takes up to 90 days. Monitor edits regularly to ensure compliance, accuracy, and sourcing integrity. Disclose any Conflict of Interest (COI) on your user page or Talk page.
Wikipedia page creation is not a self-publishing process but a structured editorial review system. Using Draftspace, complying with notability standards, and submitting through Articles for Creation protects the page from deletion and establishes a stable entity foundation for long-term search and AI visibility.
What Does Wikipedia Consider Notable Enough For a Page?
Wikipedia considers a topic notable enough for a page when it has received significant coverage in multiple reliable, independent, secondary sources. Wikipedia notability refers to documented, in-depth coverage by reputable publications such as major newspapers, academic journals, books from established publishers, or recognized industry media. The General Notability Guideline (WP:GNG) requires that coverage be substantial, not trivial mentions, and independent of the subject. Press releases, self-published blogs, routine announcements, and company-owned content do not establish notability.
Notability requires sustained attention rather than temporary visibility. Coverage must analyze, describe, or evaluate the subject in detail rather than merely list it. Wikipedia reviewers typically expect at least 3 strong independent sources before approving a new article. If reliable secondary coverage does not exist, the topic does not qualify for a standalone page, regardless of business size, funding amount, or marketing presence.
What Kind of Third-Party Coverage Does a Company Need To Qualify For Wikipedia?
A company needs significant, in-depth coverage in multiple reliable, independent, secondary sources to qualify for a Wikipedia page. Wikipedia requires substantial analysis or discussion of the company in at least 3 to 5 strong publications, though 10 to 20 total references often strengthen approval probability. Qualifying coverage includes full-length articles, investigative features, scholarly research, or detailed book sections focused specifically on the company.
Sources must be independent and maintain editorial oversight. Independent sources exclude employees, founders, investors, vendors, customers, and business partners. Reliable publications include major newspapers, established industry journals, and academic publishers. Press releases, sponsored content, interviews controlled by the company, product reviews without editorial oversight, and routine financial announcements do not establish notability.
At least 1 source must reach a regional, national, or international audience. Small local newsletters or niche blogs with limited circulation do not meet geographic scope requirements. Passing mentions, “top 100” lists, capital raises, mergers, acquisitions, exchange listings, and routine earnings reports are considered operational data rather than significant coverage.
Do You Need to Disclose Affiliation on Wikipedia?
Yes, editors must disclose paid affiliations and relevant conflicts of interest when contributing to Wikipedia. The Wikimedia Foundation Terms of Use require mandatory disclosure for anyone receiving compensation in money, goods, or services. Failure to disclose paid editing constitutes Undisclosed Paid Editing (UPE), which violates platform rules.
Editors with a Conflict of Interest (COI) must avoid direct editing and instead propose changes on Talk pages or submit drafts through the Articles for Creation process. Undisclosed advertising that mimics independent editorial content violates consumer protection laws, including standards established under the FTC Act. Non-disclosure results in content removal, account blocks, or permanent bans.
Does Wikipedia Allow AI Content?
No, Wikipedia does not allow AI-generated text to be used as published article content. Wikipedia permits limited AI-assisted workflows under human supervision, but direct generation of article text using Large Language Models is prohibited.
The Wikimedia Foundation introduced AI-assisted tools to support tasks such as translation, moderation assistance, and image restoration with disclosure. However, editors must verify all content manually. AI-generated hoaxes, fabricated citations, or synthetic paragraphs violate editorial policy and result in content removal or editor blocks. Human authorship and verifiable sourcing remain mandatory requirements.
Is Wikipedia Enough To Rank on AI Answers?
No, Wikipedia alone is not enough to guarantee ranking in AI-generated answers. Wikipedia functions as a foundational authority layer for Large Language Models, but AI visibility depends on cross-source validation, recency, entity consistency, and broader media presence.
Wikipedia accounts for a significant share of ChatGPT citations and influences Knowledge Graph construction. However, Wikipedia links use the nofollow attribute and provide no direct ranking authority to external domains. AI systems evaluate multiple data sources before inclusion. Sustainable AI visibility requires independent press coverage, structured entity alignment, and ongoing citation growth beyond Wikipedia, including ranking on ChatGPT.
Does ChatGPT Use Wikipedia as a Source?
Yes, ChatGPT uses Wikipedia as a major training and citation source. Wikipedia represents one of the most frequently cited domains in ChatGPT outputs and forms a core part of LLM factual infrastructure.
Studies analyzing millions of AI citations show that Wikipedia accounts for a large share of ChatGPT references compared to other domains. However, reliance varies by platform. Google AI Overviews cite Wikipedia less frequently, and Perplexity often prioritizes Reddit. Wikipedia remains central to ChatGPT factual grounding but does not represent the only data source.
What Other Sources Does AI Rely Besides Wikipedia?
AI systems rely on a diverse mix of social platforms, multimedia archives, academic publications, commercial databases, and geospatial datasets beyond Wikipedia. Modern AI models prioritize both structured authority sources and “living” conversational archives.
- Reddit. Reddit provides large-scale human discussion data and accounts for a high percentage of citations in AI systems such as Perplexity and Google AI Overviews. Reddit contributes experiential knowledge across medicine, finance, technology, and niche domains.
- YouTube. YouTube supplies multimedia transcripts, tutorial content, and metadata. AI models extract structured speech-to-text data to answer how-to and product-related queries.
- News and Academic Publications. Major newspapers and peer-reviewed journals provide high-authority reporting and research validation. These sources establish factual credibility across finance, science, and policy topics.
- Commercial Review Platforms (Yelp, Amazon, TripAdvisor). Review platforms provide sentiment-rich consumer data, product specifications, and behavior trends. AI models use this data for recommendation-style responses.
- Social Networks (Facebook and Similar Platforms). Social platforms contribute language usage trends, behavioral signals, and cultural context that influence conversational model outputs.
- Geospatial Data Providers (Mapbox and OpenStreetMap). Geospatial datasets power navigation, logistics, and physical-world reasoning. Structured location data improves routing, mapping, and environment-based query responses.
AI sourcing strategies differ by platform, but modern systems combine encyclopedic authority, social conversation, multimedia data, and structured knowledge graphs to generate answers. Wikipedia remains foundational, yet it operates within a broader multi-source AI retrieval ecosystem.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}