A redirector in AI traffic is an intermediate routing mechanism that sits between an AI platform citation link and the destination URL, controlling whether a referrer signal reaches the receiving analytics system. Redirectors are distinct from referrer stripping. Referrer stripping removes the HTTP Referer header at the source. A redirector introduces an intermediate step in the URL path itself (a separate domain, a server-side routing hop, or a webview behavior) that breaks the referrer chain before the user reaches the destination page.
The practical consequence is attribution loss at scale. A user who clicks a citation link in ChatGPT passes through an intermediate routing layer before landing on the destination page. The analytics tag on the destination page sees the intermediate redirect domain as the referrer, or sees nothing at all when the redirect chain applies a Referrer-Policy: no-referrer header. GA4 assigns the session to Direct or to an ambiguous Referral source with no identifiable AI origin.
AI-referred traffic grew 623% year-over-year, reaching 0.2% of total website visits according to Contentsquare analysis of 99 billion sessions, and it grows faster than any other referral channel. The majority of that growth is invisible in standard GA4 channel reporting because redirectors, referrer suppression, and webview architecture strip attribution before it reaches the analytics layer. Understanding the mechanism behind each type of attribution loss is a prerequisite for recovering it.
What Is a Redirector in AI Traffic?
A redirector in AI traffic is any mechanism that intercepts the URL path between an AI platform and the destination page and alters or destroys the referrer signal in the process. A redirector in AI traffic covers 3 distinct behaviors that are often conflated. An intermediate redirect domain that routes the click through a separate URL, a server-side Referrer-Policy header applied before the response reaches the browser, and mobile webview behavior that suppresses cross-origin referrer passing in in-app browser environments.
What makes a redirector different from a standard web redirect? A standard web redirect (301 or 302) preserves the referrer chain in most configurations. The browser passes the original referrer to the final destination unless a Referrer-Policy header explicitly strips it. An AI traffic redirector is specifically a mechanism that produces attribution loss as an outcome, whether by design (click tracking that suppresses origin data) or as a side effect of infrastructure choices (webview sandboxing). The distinction matters for recovery. Standard redirects are recoverable through referrer chain analysis. AI-specific redirectors require alternative attribution methods.
What does a redirector do to the HTTP Referer header? The HTTP Referer header (defined in RFC 9110) passes the URL of the originating page to the destination server as part of the HTTP request. A redirector breaks this chain by interposing a URL that either has no Referer of its own (because it is the root of the chain) or applies a Referrer-Policy: no-referrer header that instructs the browser not to forward the referrer on subsequent navigation. The destination site never sees the AI platform as the origin. It sees the intermediate redirect domain, or nothing at all.
How does GA4 process a session that arrives through a redirector? GA4 reads the referrer from the HTTP request and uses it to assign the session to a source/medium channel. A session arriving through an AI redirector that strips the referrer produces a source of (direct) and medium of (none), which GA4 places in the Direct channel. A session arriving through a redirector that passes a partial referrer (the intermediate domain rather than the AI platform) lands in the Referral channel under the intermediate domain. Neither attribution is accurate, and neither is recoverable without cross-referencing server-side data.
Why do AI platforms use redirector mechanisms? AI platforms route outbound clicks through redirect infrastructure for several operational reasons. Click tracking allows the platform to measure user engagement with citations and monitor which external domains receive traffic. Privacy architecture in some platforms deliberately strips origin data to prevent destination sites from profiling users based on their AI query context. Mobile webview sandboxing (WKWebView on iOS, Custom Tabs on Android) is a default platform constraint rather than a deliberate choice. The attribution loss is a side effect of these mechanisms, not a primary goal.
What Are the Different Types of AI Traffic Redirectors?
AI traffic redirectors divide into 3 structural categories based on where in the request chain the referrer signal is broken. At the domain level (intermediate redirect URL), at the header level (Referrer-Policy), and at the rendering level (webview behavior). Each type produces the same GA4 result (Direct attribution or wrong Referral) but requires a different recovery method.
The main types of AI traffic redirectors are listed below.
1. Intermediate redirect domains. Some AI platforms route outbound clicks through a platform-owned intermediate URL before sending the user to the destination. The intermediate URL is typically a click-tracking endpoint (a subdomain or path within the AI platform) that logs the click and then issues a redirect to the final destination. The destination site sees the intermediate redirect URL as the referrer, not the AI platform origin page. ChatGPT has been documented routing clicks through intermediate OpenAI infrastructure in certain browsing contexts.
2. Referrer-Policy header suppression. Web servers respond to browser requests with HTTP headers, and the Referrer-Policy header controls what referrer information the browser forwards on subsequent navigation. A server-side Referrer-Policy: no-referrer header strips the referrer entirely; Referrer-Policy: origin passes only the domain without the path. AI platforms applying these headers to their outbound link responses strip referrer data before the browser even initiates the outbound request. The destination site receives no referrer regardless of browser behavior.
3. rel=”noreferrer” HTML attribute. The rel=”noreferrer” attribute on an HTML anchor element instructs the browser not to send a referrer header when navigating to the linked URL. Google AI Mode applies this attribute to all outbound citation links. The browser respects the attribute and strips the referrer before sending the navigation request to the destination. This is distinct from a server-side Referrer-Policy. The instruction comes from the markup of the link itself rather than from a response header.
4. Mobile webview behavior (WKWebView, Android Custom Tabs). Native AI apps on iOS use WKWebView to render in-app browser sessions. WKWebView has specific referrer-passing behaviors in cross-origin navigation contexts and does not reliably pass referrers across origin boundaries, particularly in configurations where the app sets its own webview policy. Android Custom Tabs behave similarly. A user clicking a citation in ChatGPT on iOS arrives at the destination page with no referrer, regardless of what header policy the platform server sets.
5. HTTPS-to-HTTP referrer drop. The browser security model prevents passing referrer headers from a secure HTTPS origin to an insecure HTTP destination. AI platforms operate exclusively over HTTPS. Destination sites still using HTTP receive no referrer from any HTTPS origin. AI platforms, standard browsers, and all HTTPS origins share this constraint. Legacy pages or mixed-content environments lose referrer data on this basis alone.
6. Multi-hop redirect chains. Some AI platforms serve citations through redirect chains involving more than one hop (platform click-tracker to CDN or partner domain to final destination). Each additional hop in the chain introduces another point where the referrer is either reset (the new hop has no referrer of its own) or stripped. The destination page referrer reflects the last hop in the chain, not the AI platform origin. Multi-hop chains are particularly common when AI platforms integrate with content distribution or affiliate tracking infrastructure.
What Is the Difference Between a Redirector and Referrer Stripping?
A redirector and referrer stripping are two distinct attribution-loss mechanisms that produce the same GA4 output (Direct attribution) through different technical paths. Understanding the distinction matters for the recovery strategy, because each mechanism requires a different fix.
The differences between an AI traffic redirector and referrer stripping are below.
| Dimension | AI Traffic Redirector | Referrer Stripping |
|---|---|---|
| Definition | An intermediate URL or routing layer between the AI platform and the destination | Direct removal of the HTTP Referer header at the source or browser level |
| Mechanism | Click passes through a separate domain or server hop before the destination | Referrer-Policy header or rel=”noreferrer” removes referrer before navigation |
| Intermediate URL | Present (redirect domain appears in request chain) | Absent (no intermediate step; visit appears to originate directly) |
| Server log visibility | Redirect domain IP or hostname appears in access logs | No intermediate; logs show the visit as origin-direct |
| GA4 result | Direct (if referrer stripped) or Referral under redirect domain | Direct (source: direct, medium: none) |
| Recovery method | Catch the redirect domain in the custom channel grouping or UTM parameters | Server-side tracking; behavioral proxy analysis of the Direct channel |
| Platform example | ChatGPT desktop click-tracking infrastructure | ChatGPT mobile WKWebView, Google AI Mode noreferrer attribute |
| Root cause | Platform click-tracking architecture | Privacy design, browser security model, or explicit attribute |
How does the GA4 output differ between a redirector and referrer stripping? The session-level output is often identical. Direct attribution with source (direct) and medium (none). The difference is that a redirector leaves an intermediate signal in server logs (the redirect domain appearing as a referrer before it drops), while referrer stripping leaves no intermediate signal at all. An analyst examining only GA4 data sees the same Direct attribution in both cases, where server log analysis reveals the difference.
Why does the distinction matter for recovery? Referrer stripping is not recoverable through channel grouping, because there is no referrer signal to match. Recovery requires behavioral proxies (analyzing Direct channel session quality) or alternative attribution infrastructure (server-side tagging, UTM parameters on controlled links). A redirector leaves the intermediate domain as a traceable signal in server logs and, in some cases, in GA4 Referral data. Catching the intermediate domain in a custom channel group allows partial attribution recovery without requiring server-side infrastructure changes.
Do redirectors and referrer stripping occur simultaneously? Both occur on the same visit in some configurations. ChatGPT mobile routes clicks through intermediate infrastructure (redirector behavior) and runs within WKWebView (referrer stripping behavior). The two mechanisms stack. The redirector provides an intermediate URL, and the webview behavior strips the referrer from the intermediate URL before passing to the destination. The result is a visit with no recoverable referrer signal, even in server logs.
How Do AI Redirectors Affect Website Attribution?
AI redirectors affect website attribution by systematically removing the referrer signal that GA4 uses to assign sessions to source channels, producing a reporting gap between the volume of AI-referred human visits and the volume of AI-attributed sessions in analytics.
What percentage of AI-referred visits are affected by redirector attribution loss? Attribution loss from redirectors and referrer stripping combined is substantial. Research by Loamly analyzing 20,428 visits found that 70.6% of AI-adjacent visits arrived without a referrer header and landed in the Direct channel. This figure comes from a vendor platform dataset and represents a specific measurement context, not a universal benchmark. AI-referred traffic growing at 623% YoY means the absolute volume of misattributed sessions grows proportionally with AI platform adoption.
What is the downstream effect on reporting? Attribution loss from AI redirectors produces the same reporting distortions as referrer stripping. AI platforms appear to be smaller referral sources than they actually are. Direct channel quality improves without an obvious explanation, and content investments in AI citation optimization are systematically undervalued because the traffic they drive is not attributed to the channel. Redirector-caused losses are partially recoverable through server-side log analysis, whereas referrer-stripping losses require behavioral proxy methods.
Why Does AI Traffic via Redirectors Appear as Direct in GA4?
GA4 assigns sessions to channels based on the referrer present in the incoming HTTP request and the UTM parameters attached to the URL. A session arriving through a redirector that strips the referrer has no signal for GA4 to assign. The source is (direct), the medium is (none), and the session lands in the Direct channel by default.
What is the exact sequence that produces Direct attribution from a redirector? The sequence follows four steps. First, a user clicks a citation link in an AI platform. Second, the click passes through an intermediate redirect URL that either strips the referrer via Referrer-Policy or is itself the last in the chain with no referrer. Third, the browser sends the HTTP request to the destination page with no Referer header (or with the intermediate domain as the Referer). Fourth, the GA4 tag on the destination page reads the empty or non-AI referrer, assigns source (direct), and records the session in the Direct channel.
What does the Direct channel look like for sites with high AI citation volume? Sites receiving significant AI-driven citation traffic see the Direct channel grow with above-average session quality. AI-referred users arrive with higher intent than typical direct navigators because they have already resolved their query through the AI interface before clicking. The Direct channel shows improved conversion rates, lower bounce rates, and deeper engagement on informational content pages. These signals identify the presence of AI-referred sessions within the Direct bucket without recovering the specific AI platform source.
What is the difference between Direct attribution from a redirector and organic Direct traffic? Organic direct traffic originates from users who type URLs, use bookmarks, or navigate from non-web contexts. It tends to land heavily on the homepage, product pages, and previously visited pages. AI redirector-produced Direct traffic lands on mid-funnel informational content (definitions, how-to articles, comparison pages) because AI citations target content that answers specific queries. Analyzing the direct session landing page distribution reveals whether redirector-produced traffic is present at a significant volume.
How Does the HTTP Referer Header Get Dropped During AI Routing?
The HTTP Referer header (as defined in RFC 9110) is an optional request header that browsers attach to navigation requests, containing the URL of the page the user navigated from. Its presence, absence, and content are entirely at the discretion of the browser, the originating page, and the server-side response headers.
What controls whether the Referer header is sent? Three-layer control Referer header transmission. The browser default behavior (Chrome, Safari, Firefox) sends the Referer in same-origin navigation and sends origin-only in cross-origin navigation under the strict-origin-when-cross-origin default policy. A Referrer-Policy response header from the server overrides the browser default and sets explicit rules for that specific response. A rel=”noreferrer” attribute on the anchor element in HTML overrides both the server policy and browser default for that specific link. AI platforms operate at all three layers simultaneously in different configurations.
What happens to the Referer header in a multi-hop redirect chain? Each hop in a redirect chain has its own referrer state. The browser follows a 301 or 302 redirect and sends a new HTTP request to the redirect target. The Referer for that new request is the URL of the redirect source (the previous hop in the chain), not the original AI platform page. Hop 2 sees Hop 1 as the referrer; the destination page sees the last hop before it as the referrer, not the AI platform. A chain of even two hops is sufficient to completely obscure the AI origin from destination-side analytics.
What role do webviews play in Referer header behavior? Mobile webview environments (WKWebView on iOS, Android Custom Tabs) implement their own Referer policies that differ from the policies of the same browser engine in full browser mode. WKWebView applies restrictive cross-origin Referer policies, meaning navigation from an AI app context to an external website produces no Referer even when the AI platform page does not explicitly set a Referrer-Policy header. This behavior is native to the platform SDK and is not configurable by the AI platform or the destination site.
How Do Different AI Platforms Send Traffic via Redirectors?
The major AI platforms differ significantly in their redirect and referrer behavior, with some passing referrers reliably in desktop contexts, others stripping referrers by default in mobile, and at least one applying noreferrer universally to all outbound citation links.
The referrer behavior of the major AI platforms is below.
| Platform | Desktop referrer behavior | Mobile referrer behavior | UTM parameters | GSC visibility |
|---|---|---|---|---|
| ChatGPT | UTM params added June 2025, some intermediate redirect routing | WKWebView strips referrer; arrives as Direct | utm_source=chatgpt.com on desktop citations | Not directly tracked in GSC |
| Perplexity | Passes referrer on direct citations; lower redirect rate | Partial referrer passing via Custom Tabs | No standard UTM addition | Not tracked in GSC |
| Google AI Mode | rel=”noreferrer” on all outbound links; all arrive as Direct | Same as desktop | No UTM addition | AI Mode filter in GSC since June 2025 |
| Claude | Referrer behavior varies by surface (web, API, app) | WKWebView; minimal referrer passing | No standard UTM addition | Not tracked in GSC |
| Microsoft Copilot | Bing search infrastructure passes some referrers | Moderate referrer passing | No standard UTM addition | Partially visible in GSC |
How Does ChatGPT Route Clicks to External Pages?
ChatGPT routes outbound clicks through behavior that varies by surface (desktop web, mobile app, API integrations) and has changed over time as OpenAI has adjusted its analytics and privacy architecture.
What changed about ChatGPT referral behavior in June 2025? OpenAI began appending utm_source=chatgpt.com parameters to citation links in ChatGPT desktop in June 2025. This change makes desktop ChatGPT citations partially trackable in GA4 even when the HTTP Referer header is stripped, because UTM parameters are read from the URL itself rather than from the request header. Sites with UTM-aware analytics configurations see a new source (chatgpt.com) in the campaign and source reports. This does not recover attribution for mobile or API-delivered citations, which do not receive UTM parameters.
How does ChatGPT mobile route clicks differently from desktop? ChatGPT mobile (iOS and Android apps) opens external links in native webviews (WKWebView on iOS, Custom Tabs on Android) that apply restrictive cross-origin referrer policies. The destination page receives no Referer header and no UTM parameters. The resulting session lands in the Direct channel with no recoverable attribution signal in client-side analytics. Server-side log analysis reveals that the session occurred, but cannot identify the AI platform origin without additional context.
What is the intermediate redirect behavior in ChatGPT citations? ChatGPT desktop citations in some contexts route through an intermediate OpenAI infrastructure URL before redirecting to the external destination. The destination site sees an OpenAI-related referrer in some cases, which is subsequently overwritten or stripped depending on the redirect chain configuration. The specific intermediate domain varies by ChatGPT version and citation type, as web search citations and knowledge-based citations behave differently.
How Does Perplexity Handle Outbound Link Forwarding?
Perplexity passes referrers more consistently than ChatGPT in desktop browser contexts, and its crawl-to-refer ratio (the proportion of crawl requests to actual human referrals) is lower than training-focused platforms, indicating it is more actively engaged as a referral source rather than purely as a training indexer.
How does Perplexity pass referrer data in desktop contexts? Perplexity desktop in a standard browser context passes the HTTP Referer header for direct citation link clicks, resulting in sessions attributed to perplexity.ai in the GA4 Referral channel. This behavior makes Perplexity more trackable than ChatGPT under default analytics settings. The degree of referrer passing varies by citation type and whether Perplexity applies server-side Referrer-Policy headers to specific response types.
What referrer behavior does Perplexity exhibit in mobile or app contexts? The Perplexity mobile app opens external links in webview environments with referrer behavior similar to ChatGPT mobile. Cross-origin navigation from the Perplexity app context to external destinations strips the referrer, producing Direct attribution. Users of Perplexity on mobile who click citation links produce the same Direct channel entry as ChatGPT mobile users, even though Perplexity desktop passes referrers more reliably.
Does Perplexity use intermediate redirect domains for its citations? Perplexity routes some citation link clicks through its own infrastructure for tracking purposes. Sites receiving Perplexity traffic in server logs see perplexity.ai as a referrer for direct citation clicks, but some click-tracking configurations route through Perplexity subdomain infrastructure that appears as a distinct referrer from the main platform domain. The volume of Perplexity subdomain-attributed sessions in server logs that do not match GA4 Referral counts reveals the scale of intermediate routing behavior.
Why Does Google AI Mode Apply noreferrer to All Outbound Links?
Google AI Mode, the AI-integrated search mode within Google Search that generates citation-based answers, applies rel=”noreferrer” to all outbound citation links as a deliberate architectural decision.
What is the effect of rel=”noreferrer” on a citation click in Google AI Mode? A user who clicks a citation in Google AI Mode triggers a browser navigation request where the anchor element carries rel=”noreferrer”. The browser strips the Referer header before sending the HTTP request to the destination. The destination site receives no referrer signal at the server level, and GA4 attributes the session to Direct. This behavior is universal for Google AI Mode citations regardless of destination site infrastructure or analytics configuration.
Why does Google apply noreferrer to AI Mode citations? Google applies noreferrer to AI Mode outbound links as a privacy-protective measure, consistent with its broader approach to limiting cross-site data sharing. The noreferrer attribute prevents the destination site from knowing the user navigated from a Google AI Mode result, reducing the amount of user behavior data that flows between Google and destination publishers. The side effect is that publishers lose attribution data for AI Mode-driven visits.
How does the Google Search Console AI Mode filter help despite the referrer loss? Google added an AI Mode filter to Search Console in June 2025, providing impression and click data specifically for queries answered through AI Mode. This data is available at the query and page level in the Performance report. GA4 still receives no referrer, and the sessions still land in Direct, but GSC provides the impression-side signal that confirms a page is appearing in AI Mode results. Comparing GSC AI Mode click data against unexplained Direct traffic volume is one method for estimating the attributable volume of Google AI Mode visits.
How to Track AI Traffic That Passes Through Redirectors?
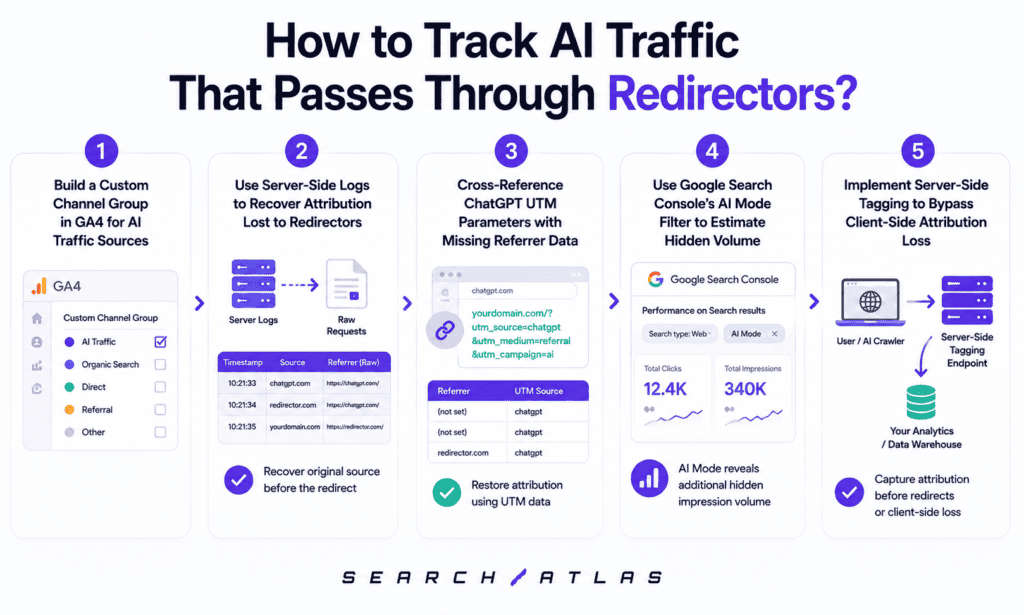
Tracking AI traffic through redirectors requires a five-step approach that combines custom channel configuration, server-side log analysis, UTM parameter cross-referencing, and GSC data alignment, addressing the fact that no single tool recovers all attribution lost to redirector mechanisms.
1. Build a Custom Channel Group in GA4 for AI Traffic Sources
A custom channel group in GA4 aggregates the attributed portion of AI referral traffic that passes through redirectors with identifiable referrer signals, replacing the fragmented default channel view with a single AI-attributed channel.
What AI platform domains should a custom channel group target? The custom channel definition uses regex matching against the session source to catch known AI platform domains. Target chatgpt\.com, perplexity\.ai, claude\.ai, gemini\.google\.com, copilot\.microsoft\.com, you\.com, phind\.com, bing\.com/chat, and any intermediate redirect domains associated with these platforms (OpenAI subdomain infrastructure, for instance). UTM source parameters added by ChatGPT desktop (utm_source=chatgpt.com) are matchable through the Source parameter in the channel definition.
What attribution does a custom channel group not recover? A custom channel group only catches attributed sessions that arrive with a matching referrer or UTM parameter. Sessions arriving through referrer-stripping mechanisms (noreferrer, WKWebView, Referrer-Policy headers) have no signal to match and land in Direct regardless of the channel grouping. The custom channel group reveals the attributed portion of AI referral traffic; it does not recover the dark traffic portion.
How do you configure a custom channel group in GA4 for AI traffic? In GA4, navigate to Admin, then Custom channel groups, then Create new. Add a condition matching Session source containing regex chatgpt\.com|perplexity\.ai|claude\.ai|gemini\.google\.com|copilot\.microsoft\.com. Add a second condition for UTM source matching chatgpt.com. Name the group “AI Referral Sources.” Apply it to all exploration and reporting views. This creates an AI-specific channel that aggregates all identifiable AI referral traffic into a single reportable view.
2. Use Server-Side Logs to Recover Attribution Lost to Redirectors
Server-side logs (nginx access logs, Cloudflare logs, Apache logs) capture the HTTP Referer header as the web server receives it, before GA4 or any client-side analytics tag processes the request. This provides the only data source that reveals intermediate redirect domains.
What server log data reveals redirector-caused attribution loss? Access logs contain three fields relevant to redirector analysis. The referer field shows what the server received as the Referer header; this reveals intermediate redirect domains that GA4 never sees. The user_agent field identifies AI crawler user-agents (GPTBot, OAI-SearchBot, Perplexity-User) that index pages but are distinct from actual user referrals. The request_uri field shows the full URL path requested, which in some cases contains UTM parameters appended by the AI platform.
How do you identify AI-referred sessions in server logs without a referrer signal? Sessions without a referrer signal that originate from AI referrals are not distinguishable from organic direct visits at the server log level alone. The analysis approach is to segment by landing page. Sessions arriving on informational, citation-likely content (definition pages, how-to articles, comparison content) with no referrer and above-average session depth are candidates for AI-referred dark traffic. This is a statistical estimate, not an exact attribution.
How do server logs help identify intermediate redirect domains? Access logs from a site receiving ChatGPT-routed traffic show the intermediate redirect domain as the Referer header value in some visits. Filtering for referer values containing OpenAI infrastructure domains (typically subdomains of openai.com) and comparing the volume against GA4-reported chatgpt.com referrals reveals the proportion of ChatGPT traffic arriving through the intermediate domain versus passing a direct referrer. Visits attributed to the intermediate domain in server logs are misclassified in GA4 and represent recoverable AI attribution.
3. Cross-Reference ChatGPT UTM Parameters with Missing Referrer Data
ChatGPT desktop citations began appending utm_source=chatgpt.com to outbound links in June 2025. This change creates a partial recovery mechanism for desktop ChatGPT traffic even when the Referer header is absent.
How do UTM parameters survive a redirect chain where the Referer header does not? UTM parameters are appended to the destination URL itself as query string parameters, not to the HTTP request headers. A redirect chain strips Referer headers but passes the URL (including its query string) to the final destination unchanged, unless the redirect infrastructure explicitly strips query parameters. This means utm_source=chatgpt.com survives the redirect hop that strips the Referer, and GA4 reads it from the URL at the destination.
What GA4 data reveals when UTM parameters are cross-referenced with missing referrer data? Cross-referencing requires two comparisons. First, count sessions with utm_source=chatgpt.com in GA4 (attributed desktop ChatGPT citations). Second, analyze the Direct channel for sessions landing on pages known to appear in ChatGPT citations, arriving within the same time window. The ratio of UTM-attributed sessions to estimated Direct-channel ChatGPT sessions indicates the proportion of ChatGPT traffic that the UTM parameter recovery mechanism captures versus the volume still arriving as dark direct traffic.
What are the limitations of UTM parameter recovery for ChatGPT traffic? UTM parameters added by ChatGPT only appear on desktop citations in the standard ChatGPT interface. Citations in ChatGPT mobile, API-delivered responses, and enterprise ChatGPT integrations do not receive UTM parameters. The UTM recovery captures a meaningful portion of ChatGPT desktop traffic but leaves mobile and API-delivered traffic unattributed. For most sites, mobile ChatGPT traffic is a significant share of total ChatGPT volume.
4. Use Google Search Console’s AI Mode Filter to Estimate Hidden Volume
Google Search Console added an AI Mode filter to its Performance report in June 2025, making it the primary tool for measuring impressions and click volume from Google AI Mode citations, despite the fact that GA4 receives no referrer from AI Mode outbound links.
What does the GSC AI Mode filter show? The AI Mode filter in Search Console Performance reveals the impressions and clicks generated by queries answered through Google AI Mode. Data is available by query, page, date, and device, using the same dimensions as standard organic search data. The filter isolates AI Mode performance from standard organic performance, allowing comparison of CTR, impression volume, and click trends for the same page and query combinations across both modes.
How do you use GSC AI Mode data to estimate GA4 attribution loss? Take the click count from the GSC AI Mode filter for a given page over a defined period. Compare it against the total Direct channel sessions landing on the same page in GA4 over the same period. Subtract any Direct sessions attributable to organic brand navigation (estimated from branded query volume in GSC). The residual represents an upper bound on the Google AI Mode-originated Direct sessions in GA4. This is an estimate; not every GSC-reported click matches a GA4-recorded session due to bot filtering and JavaScript execution differences.
What does a growing gap between GSC AI Mode impressions and GA4 Direct traffic mean? A growing gap between AI Mode impressions in GSC and Direct traffic volume in GA4 reflects one of two conditions. Impressions are growing, but click-through rate is falling (zero-click inflation from AI Overviews), or impressions and clicks are growing, but GA4 is failing to record the sessions due to client-side analytics failures or bot misclassification. Distinguishing the two requires server-side log comparison. Server logs recording more sessions than GA4 from the relevant time windows indicate a GA4 recording failure rather than a true session decline.
5. Implement Server-Side Tagging to Bypass Client-Side Attribution Loss
Server-side tagging moves the analytics data collection from the browser to a server environment controlled by the publisher, capturing attribution signals that client-side JavaScript execution cannot.
What is server-side tagging, and how does it differ from standard GA4 implementation? Standard GA4 implementation fires a JavaScript tag in the browser that reads the referrer from the browser context and sends an event to the GA4 data collection endpoint. Server-side tagging routes the analytics request through a publisher-controlled server that reads the HTTP request before forwarding to GA4. The server-side tag reads the Referer header at the server level (the same value as server logs), meaning it captures intermediate redirect domain referrers that the browser-level JavaScript does not preserve.
What attribution does server-side tagging recover that standard GA4 misses? Server-side tagging recovers the intermediate redirect domain as the referrer for sessions arriving through redirectors that pass an intermediate Referer to the destination server. A session routed through an OpenAI intermediate domain that passes that domain as the Referer reaches the server-side tag with the intermediate domain visible. The server-side tag captures it and maps it to the ChatGPT source in a custom channel definition. Sessions arriving with no Referer at all (WKWebView, noreferrer attribute) are not recoverable even through server-side tagging.
What infrastructure does server-side tagging require? Server-side tagging requires a server or container environment (Google Tag Manager server-side, Cloudflare Workers, or a custom server middleware) positioned between the destination page and the GA4 endpoint. The publisher controls and operates this infrastructure. Implementation requires modifying the GA4 tagging configuration to route events through the server-side container rather than directly to Google. The investment is substantial relative to client-side tagging, and the benefit applies specifically to the portion of attribution loss caused by redirector intermediate domains rather than by referrer stripping.
What Are the Best Practices to Reduce Attribution Loss from AI Redirectors?
Reducing attribution loss from AI redirectors requires a combination of technical tracking improvements, behavioral analysis, and content strategy adjustments that together provide a more complete picture of AI-driven traffic than any single method produces.
1. Create Dedicated AI Traffic Channel Groupings Inside Analytics Platforms
The most immediately actionable step is building a custom channel group that consolidates attributed AI referral traffic from all platforms into a single reportable view, separate from the Referral and Direct channels.
What is the impact of a unified AI channel grouping on attribution reporting? A unified AI channel grouping aggregates sessions that currently appear fragmented across Referral (chatgpt.com, perplexity.ai, claude.ai), Unassigned (partial UTM matches), and Direct (dark traffic proxy segments). The grouping does not recover dark traffic but makes the attributed portion of the AI referral traffic reportable as a single line item. Teams gain visibility into AI channel trends, platform distribution, and engagement metrics without the fragmentation that makes total AI traffic volume undercountable in the default channel taxonomy.
How often should AI channel groupings be updated? AI platform domain lists evolve as new platforms launch and existing platforms change their referral infrastructure. A custom AI channel group built in Q3 2025 does not automatically include platforms that launched in Q1 2026. A quarterly review cadence adds new AI platform domains, updates regex patterns for platforms that have changed their outbound linking infrastructure, and checks whether UTM parameter conventions have been added or modified by platforms (as ChatGPT did in June 2025).
2. Investigate Unexplained Direct Traffic Spikes Linked to AI Citations
Direct traffic spikes that correlate with AI citation volume increases are the primary behavioral signal of AI redirector-caused attribution loss in GA4.
What constitutes a meaningful Direct traffic spike linked to AI citations? A meaningful spike is a Direct channel volume increase of 10% or more week-over-week that affects landing pages consistent with AI citation content (informational articles, definition pages, how-to content) without a corresponding increase in branded search volume, email send volume, or social media referrals. The coincidence of a Direct traffic spike with an increase in AI citation share of voice (measured via LLM Visibility or equivalent tools) is the strongest signal that the spike is AI-driven rather than brand-organic.
What actions follow confirmation of a Direct traffic spike as AI-driven? After confirming the spike is AI-driven through behavioral analysis (high engagement, informational landing pages, correlation with citation SOV increase), the next step is to identify which AI platform is driving it. Cross-reference the spike timing against any UTM-attributed ChatGPT sessions, against server log referrer analysis, and against GSC AI Mode filter data. The combination of these three data sources narrows the probable source to a specific platform or set of platforms.
3. Collect Self-Reported Attribution Through Post-Conversion Surveys
Post-conversion surveys asking users how they discovered the site provide a self-reported attribution signal that captures dark AI traffic and redirector-attributed traffic that analytics tools miss.
What does post-conversion survey data reveal that GA4 attribution does not? Survey data captures the full user journey, including AI touchpoints that leave no analytics trace. A user who discovered the site through a ChatGPT citation visited three times as Direct over two weeks, and converted on the fourth visit, as Direct is attributed entirely to Direct in GA4. The survey response “I found you through ChatGPT” recovers the actual discovery channel. Aggregated across a sample of conversions, survey data reveals the distribution of AI platform discovery that analytics infrastructure cannot capture.
How do you implement post-conversion survey attribution tracking? Place a one-question survey on post-conversion pages (thank you pages, order confirmations, onboarding screens) asking “How did you first hear about us?” with answer options that include the major AI platforms (ChatGPT, Perplexity, Google AI Mode, Claude). Record responses alongside the GA4 session ID and attribution data. Comparing the distribution of survey responses against GA4 attribution for the same conversion events quantifies the gap between reported attribution and actual attribution.
4. Measure Macro Revenue Trends Instead of Session-Level Attribution Alone
Session-level attribution is structurally incomplete for AI traffic. Macro revenue trend analysis provides a complementary view that does not depend on referrer signals.
What macro signals reveal AI-driven business impact that session attribution misses? Three macro signals correlate with AI traffic impact without requiring session-level attribution. First, branded search volume in Google Search Console reflects downstream brand discovery from AI citations (zero-click AI Mode impressions where no click occurred, for instance). Second, Direct channel revenue trends, when segmented by landing page type (informational versus transactional), reveal the AI-referred contribution to overall revenue without isolating the specific platform. Third, the correlation between the AI citation share of voice increases (measured over time) and overall website revenue trends provides a platform-independent measure of AI traffic value.
How do you build a macro attribution framework for AI traffic? Track four time-series metrics monthly. First, AI citation SOV from LLM Visibility or equivalent. Second, Direct channel conversion volume from informational landing pages. Third, branded search impression volume from GSC. Fourth, total revenue or goal completions from GA4. Plotting these four series against a shared timeline reveals the lag structure between AI exposure (citation SOV), AI-driven discovery (branded search and Direct traffic), and business outcomes (conversions). The lag typically runs 2–6 weeks from citation SOV increase to revenue impact.
5. Optimize Content Structure for AI Extraction and Generative Citation
Content that AI systems extract accurately and cite consistently generates more referral traffic, both attributed and unattributed, than content that AI systems paraphrase or ignore.
What content characteristics increase AI citation frequency for a given page? Direct definitions in the first one to two sentences of each section, question-answer pairs that are self-contained without surrounding context, entity-explicit language that avoids pronoun-dependent phrasing, and factually dense content with verifiable claims all increase the probability that an AI system cites the page with a URL rather than paraphrasing its content without attribution.
How does OTTO SEO contribute to the content optimization pipeline for AI citation? OTTO SEO connects to Google Search Console to monitor query-level performance data, detects pages that appear in AI Mode impressions but generate low click volume (a signal that the page is being surfaced but not cited with a clickable link), and applies live on-page optimizations to heading structure, entity completeness, and schema markup. These optimizations improve the probability that AI platforms cite the page as a source with a URL rather than using it as training context without attribution.
7. Build External Reviews, Mentions, and Authority Signals for AI Validation
AI platforms use off-site signals (external citations, third-party reviews, domain authority indicators) to determine which sources are reliable enough to cite in user-facing responses. Stronger off-site authority increases citation frequency across all AI platforms.
What off-site signals do AI platforms use to validate citation sources? AI systems assess source reliability through a combination of signals that overlap with traditional domain authority factors. External citations from credible domains (academic, journalistic, industry-specific), positive third-party reviews and mentions in contexts the AI system has indexed, and consistent brand entity disambiguation across public knowledge bases (Wikipedia, Wikidata, Google Knowledge Graph) all increase the probability of citation. Domain Power in SearchAtlas measures the external link authority signal that AI platforms use as one of their source-quality inputs.
How do you build authority signals specifically for AI citation eligibility? Focus external link acquisition on contexts where AI systems are likely to read and index the citations. Academic and research publications that reference the brand, technology media coverage, industry directories with editorial review processes, and structured data entries in public knowledge bases provide authority signals that AI training pipelines consume. Unlinked brand mentions in high-authority content are indexable by AI crawlers and contribute to entity recognition without requiring a hyperlink.
8. Run Incrementality Tests to Measure Hidden AI-Driven Influence
Incrementality testing measures the causal impact of AI citation on business outcomes by comparing outcomes in periods or geographies with varying levels of AI exposure.
What is an incrementality test in the context of AI traffic attribution? An incrementality test isolates the causal contribution of AI citations by holding one variable constant while varying another. A geographic incrementality test identifies markets where AI citation SOV for a target keyword is significantly higher or lower, compares conversion rates and branded search volume across markets while controlling for other traffic sources, and attributes the difference to AI citation influence. A positive difference in the high-SOV market that correlates with the citation SOV gap is evidence of AI-driven incremental impact.
How do you interpret incrementality test results for AI attribution? The incrementality test produces a measure of AI-driven impact that does not depend on session-level attribution. The test does not tell you which GA4 sessions were AI-influenced; it tells you what business outcomes would have been lower without the AI citation presence. This is the appropriate unit of analysis for a channel that generates dark traffic and zero-click discovery patterns that do not register in session attribution. Incrementality replaces “how many sessions came from AI” with “what revenue lift is attributable to AI exposure.”
What Tools Help Identify AI Traffic Routed via Redirectors?
Identifying AI traffic routed via redirectors requires tools at multiple layers of the analytics stack, from server-side log analysis at the HTTP request level to AI-specific citation monitoring at the platform level.
The main tools for identifying AI traffic routed via redirectors are listed below.
1. Search Atlas (OTTO SEO and LLM Visibility). Search Atlas provides two capabilities directly relevant to redirector attribution recovery. The Search Atlas LLM Visibility tool monitors brand citation frequency across ChatGPT, Perplexity, Claude, and Gemini, producing the citation share of voice signal that correlates with dark AI traffic volume in the Direct channel. OTTO SEO connects to Google Search Console to identify pages with AI Mode impressions and applies on-page optimizations to increase citation frequency and the probability of attributed (UTM-tagged or referrer-passing) click-throughs.
2. Google Search Console (AI Mode filter). Search Console with the AI Mode filter (available since June 2025) provides impression and click data for Google AI Mode citations. This is the only GSC-native tool that directly measures AI Mode-driven traffic, despite the fact that all AI Mode clicks arrive as Direct in GA4. Use the AI Mode filter data to estimate the volume of Google AI Mode Direct traffic and to compare page-level citation performance over time.
3. GA4 with custom AI channel groups. GA4 with a custom AI Referral channel group catches attributed AI platform referrals that currently fragment across the Referral, Unassigned, and Direct channels. The custom group captures UTM-tagged ChatGPT desktop citations that post-date the June 2025 UTM parameter rollout. This is the first tool to configure, as it recovers attribution without requiring infrastructure changes.
4. Server-side log analysis (nginx access logs, Cloudflare logs, Splunk). Server-side access logs are the only source that reveals intermediate redirect domain referrers that GA4 never sees. Filter logs for referer values containing known AI platform domains and their associated infrastructure subdomains. Compare referrer counts in server logs against GA4-attributed AI referral sessions for the same period to quantify the attributable gap. Log analysis separates AI crawler traffic (GPTBot, OAI-SearchBot, Perplexity-User user-agent strings) from AI referral traffic (human visit requests with AI platform referrers).
5. Cloudflare Analytics. Cloudflare sits at the edge network layer and captures all HTTP requests before JavaScript execution, providing a traffic baseline independent of GA4 bot filtering and client-side tag execution. Cloudflare bot analytics categorize traffic by bot type, separating AI crawler activity from human session activity. For sites experiencing redirector-related attribution loss, Cloudflare reveals the volume of requests arriving with intermediate AI redirect domain referrers before those referrers are overwritten in the browser context.
6. Google Tag Manager (server-side container). Server-side GTM moves the analytics data collection layer to a publisher-controlled server, capturing Referer values at the server level before client-side processing strips or loses them. This enables recovery of intermediate redirect domain attribution that standard GA4 misses. Server-side GTM requires separate infrastructure and configuration effort; it is most valuable for sites where AI traffic volume makes the attributable recovery substantial.
7. Hotjar or Microsoft Clarity. Session recording tools provide behavioral evidence of navigation patterns consistent with AI referral activity. Users arriving through AI citations on mobile (where webview referrer stripping is universal) exhibit characteristic browsing patterns: deep scrolling on informational content, low return visit rates, and high time on specific sections matching the AI citation context. This behavioral signature complements quantitative attribution analysis without recovering the platform-level source.
8. Custom UTM tracking infrastructure. For AI-accessible content you control (AI platform profile pages, direct submission portals, sponsored AI platform placements), UTM-tagged URLs eliminate the attribution gap for those specific touchpoints. This does not solve the referrer stripping problem for organic AI citations but establishes a benchmark for what attributed AI referral session behavior looks like, useful for calibrating behavioral proxies for the unattributed dark traffic portion.
How Does GA4’s Native AI Assistant Channel Work?
GA4 introduced a native “AI Assistants” default channel grouping in May 2026, creating a built-in channel definition that captures AI platform referral traffic without requiring manual custom channel configuration.
What does the GA4 AI Assistants channel capture? The GA4 AI Assistants channel matches sessions where the source is an identified AI platform domain (chatgpt.com, perplexity.ai, claude.ai, and other platforms in the channel definition list) or where the UTM source matches known AI platform parameters. It automates the custom channel group that previously required manual configuration, applying the attribution logic to all new sessions after the launch date.
What does the GA4 AI Assistants channel not capture? The AI Assistants channel does not recover sessions that arrived as Direct before May 2026 and does not retroactively reclassify existing Direct channel history. It does not recover sessions arriving through referrer stripping (noreferrer, WKWebView, Referrer-Policy headers) because those sessions have no referrer signal to match against the channel definition. The channel catches the attributed portion of AI referral traffic; it leaves dark AI traffic in the Direct channel unchanged.
Does the GA4 AI Assistants channel solve the redirector attribution problem? The GA4 AI Assistants channel solves the channel fragmentation problem (AI platform traffic appearing under multiple Referral entries and UTM sources) but does not solve the redirector attribution problem. Sessions arriving through referrer-stripping redirectors (Google AI Mode noreferrer, ChatGPT mobile WKWebView, server-side Referrer-Policy headers) still arrive as Direct. The channel is a reporting improvement, not a recovery mechanism for dark AI traffic.
How Much AI Traffic Is Lost to Redirector Attribution Gaps?
The volume of AI traffic lost to redirector attribution gaps is substantial and grows proportionally with overall AI referral traffic growth.
What data exists on the scale of AI redirector attribution loss? A detailed analysis of 20,428 visits found that 70.6% of AI-adjacent visits arrived without a referrer header and landed in the Direct channel. This figure is from a vendor platform dataset and represents one measurement context, not a universal benchmark. An analysis of 99 billion sessions found AI-referred traffic grew 623% year-over-year to 0.2% of total website visits, with most of that growth occurring in channels (mobile, in-app, AI Mode) where referrer stripping is the dominant behavior. The combination of rapid growth and high referrer-strip rates means the absolute volume of misattributed AI sessions grows faster than the volume of correctly attributed ones.
How is the redirector attribution gap expected to change as AI platform adoption grows? AI referral traffic volume is increasing across all platforms. ChatGPT holds 76 to 87% of AI referral traffic share, depending on the measurement dataset, and its total referral volume grows as the user base expands. The proportion of that traffic arriving through referrer-stripping channels (mobile, in-app, API integrations) is stable or growing as AI app usage outpaces AI web usage. Without infrastructure-level recovery measures (server-side tagging, UTM parameter coverage expansion), the attribution gap widens in absolute terms even as the percentage loss remains constant.
Does ChatGPT Use an Intermediate Redirect Domain?
ChatGPT routes some outbound citation clicks through OpenAI infrastructure before reaching the destination, with the specific behavior varying by surface and citation type. Desktop web ChatGPT in standard browsing contexts passes the referrer directly in some citation types (with utm_source=chatgpt.com appended since June 2025) and routes through an intermediate domain in others. The intermediate routing is most consistently documented in web search citation results, where ChatGPT serves links that pass through its click-tracking infrastructure before redirecting to the external destination.
Mobile ChatGPT routes all outbound clicks through WKWebView (iOS) or Custom Tabs (Android), stripping the referrer regardless of whether an intermediate domain is involved. The most reliable way to detect intermediate redirect behavior is server-side log analysis. Visits appearing in logs with an OpenAI subdomain as the referrer that do not appear in GA4 as chatgpt.com referrals represent intermediate redirect-attributed sessions.
Can the Redirect Chain Length Affect Whether AI Tools Cite a Page?
Redirect chain length does not directly affect whether an AI platform cites a page, but it affects the quality of the crawl data the AI platform has available to assess the page. AI platforms crawl destination URLs to index content for citation consideration. A page behind a multi-hop redirect chain (301 to 302 to final URL) is crawlable as long as each hop resolves within the crawler timeout and each hop is accessible to the AI platform user-agent. Redirect chains increase crawl latency, and some AI crawlers apply strict timeout limits.
A page that times out during a deep redirect chain is indexed with incomplete data or not indexed at all, which reduces its citation probability. The practical implication is that pages with clean canonical URLs and no unnecessary redirect chains are more reliably indexed and more consistently cited than pages with multi-hop redirect structures.
Is AI-Referred Traffic Consistently Underreported in Standard Analytics?
AI-referred traffic is structurally underreported in standard GA4 analytics under default configurations, and the underreporting is consistent across platforms and time. The mechanisms that cause underreporting (referrer stripping in mobile webviews, noreferrer attributes on AI Mode citations, server-side Referrer-Policy headers, intermediate redirect domain attribution) are stable architectural features, not temporary behaviors. They produce the same attribution loss with each visit.
The scale of underreporting varies by platform (desktop ChatGPT with UTM parameters is partially recoverable; Google AI Mode is not recoverable through client-side analytics) and by device, as mobile traffic is uniformly underreported while desktop is partially reported. Without server-side tagging, UTM parameter coverage on controlled touchpoints, and behavioral proxy analysis of the Direct channel, the standard analytics view of AI-referred traffic represents the attributed minority of actual AI-driven visits.











