Entity-based search is a search engine optimization approach that treats entities (people, places, things, concepts) as the central element for content optimization, replacing literal text matching with deep semantic understanding of concepts and their relationships. Google launched its Knowledge Graph in 2012, growing entity knowledge from 570 million entities and 18 billion facts to 8 billion entities and 800 billion facts in less than 10 years. Google’s Knowledge Graph contains 1.6 trillion facts about 54 billion entities as of May 2024. AI Overviews (SGE) trigger for 15-25% of Google searches in 2024, and entity optimization proves 3x more effective than keyword-based SEO in AI-driven search visibility.
Content optimized for entity salience, a score from 0-1 reflecting semantic centrality, demonstrates a significant impact. One entity-optimized document achieved a 0.71 primary entity salience score (up from 0.38), resulting in a 156% increase in organic traffic within 90 days and rankings for 340+ keywords (up from 89). Pages with valid schema markup are 2-4 times more likely to appear in AI Overviews, and ChatGPT responses citing structured pages score 30% higher for accuracy and completeness. Adding statistics, quotations, and citations to a page improved generative engine visibility by up to 40%, and content updated within 30 days earns approximately 3x more AI citations than older content.
Entity-based search is projected to be the primary metric for search rankings by 2026 and beyond, with 66% of consumers believing AI will replace traditional search within five years. The ROI of advanced schema implementation involves two main outcomes. Advanced schema produces a 300% potential improvement in LLM response accuracy with enterprise Content Knowledge Graphs (CKGs). Sites deploying deeply nested, error-free schema observe a 20-40% traffic lift. Topic clusters drive approximately 30% more organic traffic and hold rankings 2.5 times longer, with one cluster ranking for 1,100+ keywords and generating roughly 100 organic clicks on weekdays.
What Is Entity-Based Search?
Entity-based search is a search engine optimization approach that focuses on entities as the central element for content optimization, evaluating meaning rather than collections of words. Entity-based search moves beyond literal text matching to deep semantic understanding of concepts and their relationships. Entity-based search aims for a more accurate method for search engines to understand user intent.
What is the origin of entity-based search? The concept of “things, not strings” originated from a Google blog post announcing the Knowledge Graph. Google purchased Freebase on July 16, 2010, marking its first major step towards its current entity search system. Google launched its Knowledge Graph in 2012, shifting away from keyword-centric SEO. Google later worked to merge Freebase into Wikidata and partnered with Bing and Yahoo to create Schema.org to build entity knowledge for unstructured data. Google’s entity knowledge grew from 570 million entities and 18 billion facts to 8 billion entities and 800 billion facts in less than 10 years.
What distinguishes entity-based search from keyword-based SEO? Entity-based search distinguishes itself from traditional keyword-based SEO by optimizing for the context in which keywords are used, considering intent and relationships between different entities. Entity-based search prioritizes mentions and human discussion over keyword counts. Entity-based search focuses on context and relationships rather than text string matching. Entity-based search emphasizes understanding the meanings behind words (entities) that search engines recognize.
What are the key components of entity-based search? There are four key components of entity-based search. These are listed below.
- Entity identification maps content to knowledge graphs by explicitly mentioning relevant entities within content.
- Structured data (Schema Markup) connects established and related entities in content to search engine knowledge graphs, improving content discoverability.
- Topical authority and relevance position a site as an authority by creating comprehensive, authoritative content around a wider entity.
- E-E-A-T Signals (Experience, Expertise, Authoritativeness, Trustworthiness) tell AI systems which entities deserve visibility, enhancing brand credibility.
What are the key characteristics of entity-based search? There are three main characteristics of entity-based search. Semantic understanding evaluates meaning rather than collections of words, allowing search engines to understand search intent with greater accuracy. Contextual relevance emphasizes optimizing for the meanings behind words that search engines recognize, leading to higher rankings for topics rather than individual keywords. Knowledge graph integration maps entities into structured systems, connecting related information across the web for reliable retrieval.
How does entity-based search form a web of relationships within the digital ecosystem? Entity-based search forms three main relationships within the digital ecosystem. Dependencies rely on sophisticated algorithms that understand and categorize entities and their relationships (distinguishing “Apple” the fruit from “Apple” the company). Entity-based search requires structured data from sources (Wikipedia, Wikidata, Schema.org) to build comprehensive entity knowledge. Enablement allows AI-driven search to build a model of the world composed of entities and their connections. Competition with traditional keyword-based SEO offers long-term SEO stability and resilience against algorithm changes by aligning with Google’s focus on quality and context.
What Counts as an Entity in a Search System?
An entity is a uniquely identifiable object or concept characterized by its name(s), type(s), attributes, and relationships to other entities. An entity represents a singular, unique, well-defined, and distinguishable thing or concept, unlike a keyword (a string of text). Knowledge systems assign entities unique identifiers (“mid” for Freebase, “qid” for Wikidata) to build confident models of what an entity is and how it relates to other entities.
What are the defining characteristics of an entity? The defining characteristics of an entity involve unique identifiability, singular nature, and machine-readable concept status. An entity exists only when present in an entity catalog, which assigns a unique ID like “MREID=/m/23456” or “KGMID=/g/121y50m4” for Google. Entities act as the central organizational element in knowledge databases (the Knowledge Graph), around which all information is arranged.
What are the key components of an entity? The key components of an entity involve its attributes, types, and relationships to other entities. Attributes are properties describing an entity. Larry Page’s “Country of citizenship (United States)” or “Date of birth (March 26, 1973)” are examples. Entity types, classes, or domains group entities with similar properties. Approximately 160 entity types are identified in “Extended Named Entity” research. Relationships define connections between entities, forming a network of interconnected information.
What are common types and examples of entities? Common types of entities involve persons, places, things, businesses, organizations, products, services, brands, institutions, abstract concepts, ideas, events, dates, colors, and objects. Specific examples of entities involve “Barack Obama” (person), “Eiffel Tower” (place), “Google” (organization), “iPhone 17” (product), “Artificial intelligence” (concept), “Super Bowl” (event), “January 1, 2024” (date), and “Red” (color). Intent clusters, which emerge as a topic, are better understood and represent entities within SERP features.
What are prominent entity catalogs and knowledge bases? Prominent entity catalogs and knowledge bases involve Wikipedia, Wikidata, DBpedia, Freebase, Yago, Google My Business, and the CIA World Factbook. Wikidata underpins data used in Wikipedia and acts as an interface for Google’s Knowledge Graph. Freebase, started in 2005 by Metaweb, was sold to Google and formally closed in 2016, with its data integrated into Google’s Knowledge Graph.
What are the data structures for entities? The data structures for entities involve unstructured entity descriptions, semi-structured settings, and structured data. Unstructured entity descriptions require recognition and disambiguation of references to other entities, with directed edges (hyperlinks) added. Semi-structured settings (Wikipedia) often provide explicit links to other entities. Structured data (Google’s Knowledge Graph) uses RDF triples to define a graph where subject and object resources (URIs) are nodes and predicates are edges, serving as Google’s number one data source.
How Entities Represent Real-World Concepts?
Entities represent objects or concepts important in a system, capable of independent existence, uniquely identifiable, and able to store data. Entities abstract real-world complexities, distinguishing themselves from others. Entities exist either physically (a house, a car) or logically (a house sale, a customer transaction). The term “entity” commonly functions as a synonym for “entity-type,” as a category, “computer,” or “employee.”
What are the fundamental characteristics of entities? Fundamental characteristics of entities involve independent existence, unique identifiability, and the capacity to store data. Entities are abstractions from real-world complexities, distinguishing themselves from other objects or concepts. Entities exist either physically (a house, a car) or logically (a house sale, a customer transaction).
How do entities relate to entity-types and instances? Entities relate to entity-types as specific instances of a broader category. An entity-type represents a category (computer, employee), while an entity strictly refers to an instance of that entity-type (a specific computer). Entities are conceptualized as nouns in a linguistic analogy, representing concrete or abstract concepts.
How are real-world entities modeled as classes in object-oriented programming? Real-world entities are modeled as classes in object-oriented programming, serving as blueprints for objects. Classes encapsulate attributes (data) and methods (behaviors) associated with those entities. The initial step in modeling involves identifying key entities by examining nouns in problem descriptions. Each class represents a meaningful entity and encapsulates all related data and behavior. A Car class involves attributes (make, model, year) with methods (drive(), brake()).
What are the attributes and identification mechanisms for entities? Attributes and identification mechanisms describe the properties or state of an entity. A Car class involves a color attribute, and a Book class involves an availableCopies attribute. Attributes are categorized into three types. Single-value attributes take one value (an employee’s first name). Multi-value attributes take multiple values (an employee’s telephone numbers) and are visually double-circled. Primary key attributes uniquely identify each entity, must not contain duplicates, and are graphically underlined (a PersonalID for an Employee). All entities, except weak entities, possess a minimal set of uniquely identifying attributes.
What are the types of relationships between real-world entities? There are four main types of relationships between real-world entities. These are listed below.
- Association (“uses-a”) describes general interaction between classes. A Driver uses a Car.
- Aggregation (Whole-Part / Independent Parts) describes one class containing objects of another, where contained objects exist independently. A Car contains Wheels.
- Composition (Strong Whole-Part / Dependent Parts) describes contained objects that do not exist independently. A Car is composed of an Engine.
- Inheritance (“is-a”) describes one class inheriting properties and behavior from another. A SportsCar is a Car.
What Is the Difference Between Entities and Keywords?
Keywords are textual strings users type into search engines, while entities are uniquely identifiable real-world things, concepts, or objects with defined attributes and relationships. Keywords focus on specific words or phrases. Entities encompass broader real-world concepts (people, places, things, ideas).
What is the comparison between keywords and entities across key dimensions? The comparison between keywords and entities spans nine main dimensions. These are listed below.
- Origin & History. Keywords originated in the early 2000s (Pre-2013), before Google’s Hummingbird update. Entities originated with Google’s Knowledge Graph launch in 2012, solidified with Hummingbird (2013) and RankBrain (2015).
- Definition. Keywords are “Words people type into Google.” Entities are a “Specific person, place, or concept.”
- Scope. Keywords focus on specific words or phrases. Entities encompass broader real-world concepts.
- Contextual Understanding. Keywords provide limited contextual understanding, relying on keyword-matching algorithms. Entities provide a nuanced understanding through semantic context and relationships.
- Representation. Keywords are textually represented (red running shoes). Entities are represented in various forms (text, images, videos, structured data).
- Search Mechanism. Keywords match text strings and rely on text signals and keyword density. Entities understand concepts and their relationships, addressing underlying user needs.
- Era of Dominance. Keywords dominated pre-2013 (Early 2000s). Entities began to dominate in 2012 (Knowledge Graph) and became the “new norm” with AI Overviews (2024).
- Optimization Tactics. Keyword optimization involves stuffing into titles, meta descriptions, and body content. Entity optimization involves structuring content around specific entities, using Schema.org markup.
- AI Understanding. Keywords are less effective for AI; keyword stuffing was rendered useless by AI Overviews (2024). Entities form the foundation for AI-driven platforms (ChatGPT, Google’s AI Overviews).
Keywords are chosen over entities under what conditions? There are three main scenarios for choosing keywords. Keywords introduce and highlight entities by reinforcing the presence of specific entities through consistent mention. Keywords enhance semantic context with related terms and long-tail variations. Keywords support structured data through integration within Schema markup, metadata, and alt text.
Entities are chosen over keywords under what conditions? There are three main scenarios for choosing entities. Entities build comprehensive content by guiding content structure for in-depth coverage. Entities enhance user experience and readability through natural language processing driven by entity understanding. Entities build authority and relevance by creating content clusters and using keywords as anchor text for internal and external links.
What is the performance and cost comparison between keywords and entities? Keywords historically focused on textual representation and text matching, with optimization centered on keyword density and placement. Keyword stuffing strategies became less effective with the rise of semantic search and were rendered useless by AI Overviews in 2024. Entities encompass a broader semantic understanding beyond textual representation, focusing on semantic context. The performance of entity-based SEO is measured by AI citations and the ability to provide answers in the Knowledge Graph. Investment in entity-based SEO yields higher ROI through improved visibility and authority in modern search.
Why Does Entity-Based Search Matter?
Entity-based search matters because it enables deep semantic understanding beyond keywords, enhances AI comprehension of user intent, improves content authority, future-proofs content for evolving AI systems, boosts B2B brand visibility, and significantly increases organic traffic. Entity-based search enabled BKMKitap.com to achieve 112% organic traffic growth.
How does entity-based search enable deep semantic understanding? Google launched its Knowledge Graph in 2012, shifting search from literal text matching to understanding underlying concepts. The Knowledge Graph contains 1.6 trillion facts about 54 billion entities as of May 2024. The Knowledge Graph allows search engines and AI systems to retrieve content based on entities rather than just exact keywords. Google’s transition from keyword-based to entity-based search took 10 years, following its 2010 acquisition of Freebase.
Why is enhanced comprehension of user intent significant? Entities are unique, distinguishable concepts (Tesla car company vs. inventor) that exist independently of language. Entity recognition allows search engines to correctly answer vague questions. The Burj Khalifa example shows entity recognition, identifying the building from “when was the tallest building in the world built.” AI systems resolve entity ambiguity (Jaguar as animal, car, or NFL team) by analyzing context, nearby terms, and the Knowledge Graph. AI systems generate more precise results for queries, “Tesla stock.”
What makes improved content authority and ranking potential crucial? Signaling relevant entities allows search engines and Large Language Models (LLMs) to recognize a site as an authority, fundamental for Semantic SEO. This recognition allows Google to rank a page for a wider range of relevant queries without exact-match targeting. Content which are entities has a better chance of ranking for related searches and for “weird” keywords sharing the same underlying intent.
How does entity-based search future-proof content for AI systems? Aligning content with how AI systems learn ensures content is easier to interpret, categorize, and reuse as search evolves. Proper entity optimization increases the chances of a brand or content being cited by AI systems. Brands not validated by credible entities are less likely to be cited. Entity records parse dozens of data points, making information accessible for AI platforms and increasing visibility for brands with properly structured data in LLM search.
Why is boosting B2B brand visibility and trust important? Entities are the “building blocks of a digital knowledge graph” for B2B executives, where brand authority is “non-negotiable” for high-value decisions in sectors (tech, healthcare, legal, finance). Entity stacking associates a brand with trusted, relevant websites and communities. Authoritative brand mentions “do most of the heavy lifting for your AI search visibility.” This approach drives brand visibility through digital connections.
How did BKMKitap.com demonstrate the impact of entity-based search? BKMKitap.com, a large Turkish bookstore, regained lost organic traffic from Google Broad Core Algorithm Updates by implementing an entity-focused SEO perspective. BKMKitap.com gained over 26,000 new queries on the first day of the November 2021 update, becoming the 6th largest e-commerce website in Turkey by SimilarWeb metrics. BKMKitap.com achieved rankings for queries never been reached in 10 years. Overall organic traffic increased by over 112% during the project timeline, with a 110% Organic Click Increase and 54% Organic Impression Increase during the September 2022 update.
How Entity-Based Search Works?
Entity-based SEO operates by understanding relationships between concepts and entities, moving beyond a sole focus on keywords. Search engines (Google) increasingly use this method for more accurate search results. Google’s evolution to a semantic search engine began with the Knowledge Graph in 2012 and a fundamental algorithm change (Hummingbird) in 2013, affecting over 90% of searches.
There are four main mechanisms behind how entity-based search works. These are listed below.
- Named Entity Recognition (NER) identifies and classifies named entities in text into predefined categories.
- Entity Linking and Disambiguation assigns unique identities to entities and resolves ambiguities.
- Knowledge Bases and Knowledge Graphs store and organize entity data with their relationships.
- Entity Salience and Ranking Signals measure how central an entity is to a document and influence rankings.
1. Named Entity Recognition

Advanced SEO software interface showcasing named entity recognition features.
Named Entity Recognition (NER) is a natural language processing (NLP) component that identifies and classifies predefined categories of objects or “named entities” within unstructured text. NER transforms raw text into structured information for various applications. The term NER was coined at the Sixth Message Understanding Conference (MUC-6) in the 1990s. By 2007, state-of-the-art NER systems for English achieved near-human performance, with the best MUC-7 system scoring 93.39% F-measure compared to human annotators’ 97.60%.
Why does Named Entity Recognition matter? NER matters because NER processes text to identify and classify entities, transforming unstructured text into structured information, a capability that underpins 80-90% of data analysis efforts. NER’s impact extends across industries. The global NLP market size is expected to grow from $18.9 billion in 2023 to $68.1 billion by 2028, with NER playing a crucial role in this expansion. NER enables information extraction from unstructured databases, chatbots, virtual assistants, social media monitoring, and automated news aggregation. NER reduces healthcare research time by 30-50% and identifies threats in cybersecurity (suspicious IP addresses, URLs).
How is Named Entity Recognition implemented? NER implementation involves four main approaches. Rule-based approaches (early 1990s) create grammatical rules based on structural and grammatical features. Machine learning approaches (late 1990s-early 2010s) train AI-driven models on labeled datasets. Deep learning approaches (2010s-present) use neural networks (RNNs, LSTM, BERT) and account for 97% of advanced NLP systems. Hybrid approaches combine rule-based and machine learning methods. NER returns entity location (offset and length) within the text and a confidence score from 0-1, facilitating downstream tasks (knowledge graph creation, question answering).
2. Entity Linking and Disambiguation
Entity linking (EL) is the task of assigning a unique identity to entities mentioned in text (famous individuals, locations, companies). Entity linking maps “words of interest” (named entities, mentions, alternative phrasings) from input text to corresponding unique entities in a target knowledge base. Entity linking is known as named-entity disambiguation (NED), named-entity recognition and disambiguation (NERD), or concept recognition.
Why does Entity Linking matter? Entity linking matters because entity linking provides more accurate search results by understanding specific entities in queries and documents (filtering out “Paris Hilton” for “Paris, France”). One customer saw a 46% increase in impressions and a 42% increase in clicks for non-branded queries on 11 test pages. Marshfield Clinic Health System saw a 32% increase in click-through rates to physician pages. Entity linking transforms unstructured information into a structured form, enabling deeper semantic analysis for sentiment analysis, content recommendation, and Retrieval Augmented Generation (RAG) implementations.
How is Entity Linking implemented? Entity linking implementation involves four core subtasks. Firstly, entity detection identifies text spans mentioning entities. Secondly, candidate generation selects possible candidates from a knowledge base (Wikipedia, Wikidata, DBPedia). Thirdly, disambiguation chooses the correct entity from the candidates. Fourthly, linking connects the disambiguated entity to a unique identifier in a knowledge base. Entity linking faces challenges, which are ambiguity (homonyms like “bank”), name variations (New York, NY, Big Apple), absence/NIL prediction, scale and speed, and multiple languages. The state-of-the-art (SOTA) for disambiguation-only on AIDA CoNLL-YAGO is Mulang et al. (2020) with 94.94 Micro-Precision.
3. Knowledge Bases and Knowledge Graphs
Knowledge bases are centralized repositories of information storing and managing enterprise knowledge, while knowledge graphs are graph-based data models representing knowledge as interconnected entities and their relationships. Knowledge bases focus on structured content for human readability. Knowledge graphs capture complex semantic relationships for machine interpretability and reasoning. The term “knowledge graph” was introduced by Google in 2012 to refer to its general-purpose knowledge base.
Why do Knowledge Bases and Knowledge Graphs matter? Knowledge bases and knowledge graphs matter because knowledge bases provide static answers for customer support systems, while knowledge graphs enable AI initiatives by providing access to procedures, policies, and contextual guidance. Knowledge graphs enhance Large Language Models (LLMs) through Retrieval-Augmented Generation (RAG) by enabling factual retrieval and preventing hallucinations. Wikipedia is a prominent example of a publicly available knowledge base. Google’s Knowledge Graph drives its search engine, while Netflix uses knowledge graphs for recommendation systems.
How are Knowledge Bases and Knowledge Graphs implemented? Knowledge bases and knowledge graphs are implemented through distinct components. Knowledge bases organize three main types of knowledge (structured knowledge in relational databases, semi-structured knowledge in collaboration tools, and unstructured knowledge as human-readable text). Knowledge graphs use three main components. Nodes represent entities (Customer ID: 12345). Edges describe relationships between nodes (a product “is manufactured at” a facility). Organizing principles capture business rules or categories. Knowledge graphs support advanced query languages (SPARQL), enabling semantic search and granular data retrieval. Knowledge graphs adhere to semantic web standards (RDF, OWL).
4. Entity Salience and Ranking Signals
Entity salience is a score assigned by Google’s entity analysis, measuring how central a specific entity (people, organizations, locations, concepts) is to a document, with scores ranging from 0-1. A score of 1 indicates high importance. Ranking signals are metrics and algorithms used by search engines to evaluate and order web pages. The concept of entity salience emerged in the 2010s, with Google engineers developing calculations as early as 2014. Google’s Natural Language API assigns salience scores using deep machine learning technology powering Google Search and Google Assistant.
Why does Entity Salience matter? Entity salience matters because entity salience is a structural judgment reflecting how central an entity is to a document’s meaning, a qualitative and contextual metric. Entity salience contrasts with keyword density, a purely lexical, quantitative metric. A 2024 industry study of 320 websites by Backlinko found pages optimized for keyword density experience 28% higher bounce rates and 19% lower average time-on-page. An entity-optimized article on “Cloud Computing Security” achieved a 0.71 primary entity salience score (up from 0.38). The article produced a 156% increase in organic traffic within 90 days. The article ranked for 340+ keywords (up from 89).
How is Entity Salience implemented through key signals? Entity salience implementation involves eight key signals. These are listed below.
- Entity Recognition identifies and assigns weight to different entities within the text.
- Significance measures the prominence and frequency of an entity in the text.
- Position rewards entities in titles, headings, opening paragraphs, and conclusions with higher salience values (0.6+).
- Contextual Relevance examines relationships between entities and the overall document context.
- Interconnectedness measures relationships between various entities within the content.
- Frequency patterns track how often entities are mentioned, weighted by context.
- Syntactic relationships weight entities as sentence subjects or objects more heavily.
- Co-occurrence patterns measure which other entities appear alongside the primary entity (Tesla with Elon Musk increases salience by up to 0.2 points).
What are the salience thresholds and timeframes for Entity Salience? Google’s NLP documentation identifies a salience threshold of 0.5 as indicative of primary topical relevance. A location salience score above 0.15 is the threshold for Google’s entity analysis to treat a page as genuinely local. Improvements in entity salience typically begin to show effects within 4-12 weeks, with stable visibility gains within 3-6 months. Entity salience is expected to be the primary metric for search rankings in 2026 and beyond.
Why Search Shifted from Keywords to Entities?
Search shifted from keywords to entities because AI systems now rank distinct, recognizable concepts (entities) rather than language-dependent, isolated words. AI Overviews (SGE) trigger for 15-25% of Google searches in 2024, demonstrating reliance on AI to interpret user intent. AI systems do not rank words; AI systems rank entities (a person, place, or thing).
Why are keywords inadequate for modern search engines? Keywords are inadequate for modern search engines because they are language-dependent, isolated, and fail to convey deeper meaning or conceptual relationships. Traditional SEO focused on keyword density and repetition, but AI systems do not rely on keyword triggers. Keyword-based search (inverted index) returns a list of hundreds to thousands of pages without understanding deeper meanings. Keyword stuffing produces “semantic noise,” not relevance. Keywords are language-dependent, requiring separate strategies for each language. AI engines retrieve ideas, not strings of text, operating on “embeddings” (mathematical representations of meaning).
How do entities and AI drive modern search relevance? Entities and AI drive modern search relevance by enabling search engines to understand meaning, interpret intent, and map conceptual relationships beyond simple word matching. Google’s Knowledge Graph, launched in 2012, allowed search engines to differentiate “Apple” (fruit) from “Apple” (company). By May 2020, Google’s Knowledge Graph contained 500 billion facts on 5 billion entities, growing to over 54 billion entities by 2024. Knowledge panels appear for approximately one-third of Google’s 100 billion monthly searches. Globally, 8.4 billion voice assistants rely on entity understanding for accurate responses. Entity optimization proves 3x more effective than keyword-based SEO in AI-driven search visibility.
What is the impact of AI search engines on content visibility? The impact of AI search engines on content visibility is a shift towards rewarding recency, citation, and structured clarity, making entity optimization foundational for sustainable visibility. AI search engines (Perplexity, GPT-4o, Google) reward content structured for confident parsing and trust. Content presented as a “wall of text with no Schema and no internal entity relationships” loses visibility in AI-driven search. A site with strong entity signals gets hallucinated or skipped if AI cannot confidently read the content. Brands lacking clear entity signals risk being ignored by AI Overviews and LLM-generated responses.
How Do AI Search Engines Use Entities?
AI search engines use entities by transforming query text and web content into numerical embeddings, enabling conceptual similarity matching rather than simple term matching. AI systems prioritize trusted entities for rankings, AI answers, and knowledge-driven results. Without E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), entity recognition exists, but visibility does not. AI interfaces summarize answers from multiple sources into a single AI-generated result.
How do AI systems understand entities? AI systems (Google SGE, ChatGPT) understand entities by transforming query text and web content into numerical embeddings. Natural Language Processing (NLP) parses human language, identifying entities, grammar, and intent. AI uses entities to move beyond language and understand the real world, disambiguating terms (“apple” as fruit or “Apple Inc.”). AI crawlers find a name on a webpage, reference their knowledge base, and identify it as an entity, looking for connected entities and attributes to create a rich, factual profile.
What mechanisms enhance entity understanding and authority? Mechanisms enhancing entity understanding and authority involve nine main elements. These are listed below.
- Google SERPs and Google Images display entity information visually.
- E-E-A-T signals establish trust and authority.
- Schema markup provides structured data clarifying entity attributes.
- Semantic relationships connect entities in the Knowledge Graph.
- Topical authority strengthens entity associations.
- Entity linking connects key concepts to recognized sources.
- Multi-source consistency strengthens AI synthesis inclusion.
- Knowledge graphs validate facts across sources.
- Google Business Profiles and Knowledge Panels identify businesses, products, and concepts as entities.
How does schema markup contribute to entity recognition? Schema markup contributes to entity recognition by providing structured data that allows search engines to clearly understand an entity, its attributes, and relationships. Schema markup creates connections to recognized entities in the Knowledge Graph, boosting semantic relevance and trust signals. Connected, structured data enables AI systems to accurately interpret content. AI engines use a private knowledge graph, built with schema markup, as an official, machine-readable identity card.
What Is Entity Grounding in AI-Generated Answers?
Entity grounding provides AI systems with a stable, citeable, and machine-readable factual foundation for entities through a Grounding Page (a structured reference page combining human-readable facts, machine-readable data, and governance rules). The purpose of Grounding Pages is to enable AI systems to identify, classify, consider, and cite an entity more reliably.
What are the primary goals of Grounding Pages? The primary goals of Grounding Pages involve four main objectives. Grounding Pages reduce hallucinations by preventing AI from filling factual gaps with plausible but wrong information. Grounding Pages prevent entity confusion by distinguishing brands, products, people, events, or methods from similar names. Grounding Pages ensure non-inclusion by guaranteeing entities are considered in relevant answers. Grounding Pages counter English retrieval bias, addressing AI tendencies to rely on English-heavy retrieval patterns.
What are the key characteristics of Grounding Pages? Grounding Pages exhibit eight key characteristics. These are listed below.
- Entity clarity defines the entity using a stable name, type, short description, canonical URL, and consistent identifiers.
- The canonical definition provides one official, short, stable definition near the top of the page.
- Cite-ready facts facilitate direct extraction through short factual passages, Q&A blocks, and fact tables.
- Source architecture uses internal links connecting canonical pages, specifications, and related entity pages.
- Machine readability provides semantic HTML, JSON-LD, descriptive headings, canonical URLs, and dateModified.
- Language coverage provides both local-language and English versions for important entity pages.
- Practical implementation designs for various organizational teams (marketing, SEO, PR, product, legal, technical). What are the implementation options for Grounding Pages?
What are the implementation options for Grounding Pages? Grounding Pages offer five implementation options. A dedicated Grounding Page acts as a standalone reference. A structured About page integrates grounding information into an existing organizational overview. A factual product or service page embeds grounding data directly within product descriptions. A standard or specification page provides technical grounding for specific standards. A maintained facts section inside an existing website updates factual information regularly. Key disciplines for all options involve stable facts, clear definitions, visible ownership, machine-readable structure, and regular updates.
How do Grounding Pages differ from other content concepts? Grounding Pages differ from other content concepts by functioning as structured reference pages, not merely additional content pages. Grounding Pages complement existing landing pages, which persuade by clarifying facts. Grounding Pages design for both human and machine readability. Grounding Pages are not identical to Schema.org; while Grounding Pages use Schema.org, Grounding Pages provide human-readable facts, disambiguation, source architecture, and governance. Grounding Pages support AI SEO and GEO, but the core goal of Grounding Pages is to reduce ambiguity, not manipulation.
How to Get Cited by AI Overviews?
Getting cited by AI Overviews requires structuring information for machine readability, enhancing technical SEO, demonstrating expertise, and meeting specific Retrieval-Augmented Generation (RAG) system criteria. This multi-faceted approach ensures content is parsed, cited, and trusted by AI models.
How does content structure and readability influence AI discoverability? Content structure and readability influence AI discoverability by making information scannable and parsable for Large Language Models (LLMs). LLMs favor clear headings, bulleted lists, and numbered lists. Content answers upfront with a short, factual TL;DR or direct answer in the first 50–70 words, as AI often pulls from this introductory section. The first 150 words on a page are exceedingly important, as LLMs’ first-pass search involves contiguous data chunks ranging from 150 to 300 words. Short paragraphs (2-3 sentences) and straightforward subject-verb-object sentences enhance machine readability.
What technical SEO and markup strategies optimize content for AI ingestion? Technical SEO and markup strategies optimize content for AI ingestion by making content contextually clear and machine-readable through structured data and efficient site performance. Schema markup (FAQ, HowTo, Article, Review schema) enhances machine readability. LLMs do not currently read HTML or Schema until a second “Agentic pass phase.” Crawlability is ensured with clean HTML, limited unnecessary scripts, and a predictable structure. Site speed is prioritized by compressing images, minifying code, and improving server response time. Mobile-friendliness is ensured with a responsive design.
How does content strategy and expertise (E-E-A-T) build AI trust? Content strategy and expertise (E-E-A-T) build AI trust by demonstrating real-world knowledge, factual accuracy, and authority. Content writes the way people ask, focusing on long-tail, question-style phrases (“how does…” or “what is…”). Real expertise is shown by which are author bios, credentials, and factual accuracy. Content builds around entities, not just keywords, by defining who/what/where clearly so AI systems cite the content as a reliable entity. Content is seeded in public spaces (Reddit, Quora, LinkedIn), as these are platforms LLMs actively crawl. Content is kept fresh by updating stats and references every 3–6 months.
What are the primary criteria for AI-specific optimization and RAG system citation? AI-specific optimization and RAG system citation prioritize content, adding structured, specific information not synthesized by AI models, along with clear entity definitions. AI Overview citation is governed by a Retrieval-Augmented Generation (RAG) system. The RAG system evaluates different signals than the organic ranking algorithm. Content optimized for organic ranking does not automatically satisfy AI Overview citation requirements.
There are two primary criteria for AI-specific optimization. Information Gain Density requires content adding structured, specific information the model cannot synthesize from its existing knowledge base. Content does not rephrase, reformat, or repackage widely documented information. Entity Structural Clarity requires content that clearly defines entities and consistently relates them to each other through canonical entity naming, explicit relationship definition, classification consistency, and predicate precision.
What are Google AI Overviews’ citation patterns and preferences? Google AI Overviews’ citation patterns and preferences pull from a wide mix of sources. Core content involves blog-style articles (approximately 46% of citations) and mainstream news (around 20%). Community content from Reddit and Quora makes up approximately 4% of citations. LinkedIn articles are the fourth most cited source. Reddit is the most-cited single site. Vendor content sees notable inclusion (approximately 7%), especially for “best X” or “top Y” queries. Wikipedia is cited sparingly (less than 1%). Page depth is favored, with 82.5% of AI citations linking to deeply nested pages rather than homepages. Brand citation count averages approximately 3-4 brands per answer.
How to Optimize for Entity-Based Search?
Optimizing for entity-based search prioritizes recognition and relevance of entities (people, places, things, concepts) rather than keywords, allowing search engines to evaluate meaning and intent beyond literal text matching. Entity-based SEO allows Google to rank a page across a broader range of relevant queries without exact-match targeting once the primary entity is understood. Entity-based SEO future-proofs content by aligning with how AI systems learn and interpret information.
There are five main strategies to optimize for entity-based search. These are listed below.
- Use Structured Data (Schema Markup) to provide explicit clues about page meaning to AI systems.
- Set Entity Home/Authority Site to establish a clear, authoritative content ecosystem.
- Create Topic Clusters to build interconnected content around a central idea.
- Implement Internal Linking to connect the meaning between pages and reinforce topical authority.
- Get External Corroboration to verify the brand as a real, trusted entity through third-party validation.
What are the core principles of entity optimization? The core principles of entity optimization involve three main concepts. Firstly, recognize entities as uniquely identifiable objects. Secondly, understand Google’s semantic search engine connection to entities and databases (Wikidata, Wikipedia). Thirdly, acknowledge that document relevance to a query is partially understood through known entities. Entity understanding is impacted by web documents. Google’s understanding changes frequently during algorithm updates. Optimization is contingent upon search intent, website context, and the primary entity associated with that context. Carolyn Shelby, principal SEO at Yoast, states that “Keyword SEO is basically working on a flat map, while entity SEO lives in three-dimensional space.” Shelby adds that “Keywords just help you appear on the map; entities determine whether you ‘shine brightly’ enough to be selected.”
What are the key levers for entity-focused SEO? The key levers for entity-focused SEO involve three main elements. The speed of publishing influences how quickly a website covers new entities. The number of articles published influences how comprehensively a website covers core entities. The depth of articles published signals a strong topical authority to search engines. Rapid and extensive content creation, combined with in-depth exploration of topics, signals strong topical authority.
How does one begin with entity optimization? Beginning with entity optimization involves three main actions. Firstly, identify the primary entity associated with a website’s core purpose. Secondly, optimize around search intent when covering a topic. Thirdly, define a small, intentional set of “things” Google associates with a brand. For Nike, the primary intent is “sports equipment.” Nike’s intent abstracts further to “personal development” or “lifestyle improvement.” Core entities involve brand entities (business name, products, services), industry entities (key industry terms and concepts), and related entities (competitors, partnerships, associated topics). Websites answer “Who is this?” (brand/author entity), “What do they do?” (offering entity), and “Who is the audience?” (audience/market entity).
1. Use Structured Data (Schema Markup)
Structured data (Schema Markup) is a standardized format providing explicit clues about a page’s meaning, acting as a bridge to communicate content meaning and structure to AI systems. Structured data allows Google Search to understand page content and gather information about entities (single, well-defined things or concepts). Structured data translates website content into entities and connects entities to other entities for search engines to understand, using Schema.org as the dictionary.
Why does structured data matter? Structured data matters because pages with valid schema markup are 2-4 times more likely to appear in AI Overviews. ChatGPT responses citing structured pages score 30% higher for accuracy and completeness. Rotten Tomatoes added structured data to 100,000 unique pages, resulting in a 25% higher click-through rate for enhanced pages. The Food Network converted 80% of pages to enable search features, seeing a 35% increase in visits. Nestlé pages showing as rich results have an 82% higher click-through rate than non-rich result pages. Structured data ensures consistent representation of brand names, product descriptions, and key facts in AI-generated responses, preventing misinterpretation.
Which format options involve structured data implementation? Structured data implementation involves three main format options. JSON-LD is a JavaScript notation embedded in a <script type=”application/ld+json”> tag within the <head> or <body> elements. JSON-LD is not interleaved with user-visible text, making nested data easier to express. Most modern implementations use JSON-LD. Microdata uses HTML tag attributes to nest structured data within HTML content. RDFa is an HTML5 extension using HTML tag attributes to describe user-visible content for search engines. Most Search structured data uses schema.org vocabulary.
What are the key structured data types for entity optimization? The key structured data types for entity optimization involve eight main categories. These are listed below.
- An organization describes a brand or company, feeding into Google’s Knowledge Panel through logo, contact details, and social profiles.
- LocalBusiness is vital for local shops, restaurants, and service providers with address, opening hours, geo, and areaServed.
- A person allows Google to recognize individuals through author markup and biographical information.
- A product is essential for e-commerce with price, stock status, ratings, and reviews.
- The article enables rich results (Top Stories) for news sites, blogs, and publishers.
- Event displays dates, times, and locations for scheduled events.
- FAQPage/QAPage expands search listings with Q&A drop-downs.
- Breadcrumb shows the site structure within Google’s results.
What are the best practices for entity-based structured data implementation? The best practices for entity-based structured data implementation involve marking up only visible, relevant content, using the most specific schema type available, and maintaining data accuracy. Required properties for an object must be involved for eligibility for enhanced display. Schema markup updates as a website changes. Consistent names for people, organizations, and products are used across the site. A “data graph” (a web of connections between all elements on a site) is built. Schema verifies authorship, credentials, and source/review history to build trust with Google and generative engines, supporting E-E-A-T. Multi-location sites have dedicated pages with unique Local Business schema markup, which are accurate NAP (Name, Address, Phone number).
What tools support structured data implementation? Tools supporting structured data implementation involve validation tools, generators, and WordPress plugins. Validation tools confirm the correctness of structured data. The Rich Results Test validates structured data and previews features in Google Search. The Schema Markup Validator (validator.schema.org) provides clean validation of URLs or raw code. Google Search Console Enhancements report monitors the validity of pages, tracks errors, and checks rich result eligibility. Generators assist in creating structured data markup. Generator tools involve JSON-LD Schema Generator, Dentsu’s Schema Markup Generator, and Schema.dev, RankRanger’s generator, and Hall Analysis tool. WordPress plugins simplify structured data implementation. Popular plugins involve Yoast SEO, Rank Math, Schema & Structured Data for WP plugin, Yoast Local SEO, and Yoast SEO WooCommerce.
How is the effect of structured data measured? The effect of structured data is measured through before-and-after tests, AI citation tracking, schema performance metrics, and analytics. A before-and-after test selects pages without structured data that have several months of Search Console data. Structured data is added to these pages. Markup validity and Google’s detection are confirmed using the URL Inspection tool. Performance is recorded for a few months in the Performance report. Key metrics to track involve AI citation tracking (frequency of AI systems citing content, accuracy assessment, and competitive citation analysis). Schema performance metrics track rich result appearances, Knowledge Panel inclusion, featured snippet attribution, and voice search responses. Performance is segmented by schema type for deeper insights into structured data effectiveness.
2. Set Entity Home/Authority Site
Entity Home/Authority Site Optimization is a content optimization strategy built around concepts, relationships, and context rather than isolated keyword phrases. Search engines identify distinct concepts (entities) and connect these entities through the Knowledge Graph to interpret meaning and determine topical authority. The strength of entity signals determines which sources LLMs (ChatGPT, Gemini) cite, reference, and rank.
What are the core principles of Entity Home/Authority Site Optimization? The core principles of Entity Home/Authority Site Optimization involve understanding how search engines map concepts and evaluate content’s contribution to a subject’s broader ecosystem. Google Maps how concepts relate and evaluates whether content meaningfully contributes to a subject’s broader ecosystem. An entity is a “singular, unique, well-defined and distinguishable” thing or concept (a person, place, brand, concept, product), stored in Google’s Knowledge Graph. The critical factor for entity authority is whether entities are externally verified by Google, not merely the presence of connected schema.
What strategies establish an Entity Home/Authority Site? There are five main strategies for establishing an Entity Home/Authority Site. These are listed below.
- Content ecosystem and topic clusters create content explaining a topic and its relationships, focusing on context, semantics, and topical authority.
- Structured data (Schema Markup) enhances entity recognition by explicitly stating what each entity is and how each entity connects to others.
- Internal linking and semantic structure improve entity authority by allowing search engines to understand relationships between topics.
- Content quality and expertise (E-E-A-T) consistently produce thorough content connecting related topics, signaling expertise.
- Entity identification and structuring define goals, core topics, and clear entity sets for streamlined site architecture.
How do content ecosystems and topic clusters build entity authority? A content ecosystem and topic clusters build entity authority by creating content that clearly explains a topic and its relationships. Websites build a content ecosystem where related articles cover a broader topic area, rather than optimizing a single page for a single keyword. Content is organized into semantic clusters with a central pillar page on an overarching topic and several supporting articles on subtopics. All posts internally link using optimized anchor text to build semantic relationships. Each piece reinforces others through internal links and shared context, building topical authority.
How do internal linking and semantic structure improve entity authority? Internal linking and semantic structure improve entity authority by allowing search engines to understand relationships between topics. Websites optimize semantic anchor texts to encapsulate the essence and context of the linked entity’s content (“Dr. Jane Doe’s arthritis treatment approach” instead of “click here”). Websites establish logical and semantically related internal links reflecting relational depth. Websites cross-link between different entity sets (treatments and conditions) to enhance navigation. Breadcrumbs delineate site hierarchy.
How does content quality and expertise (E-E-A-T) contribute to entity authority? Content quality and expertise (E-E-A-T) contribute to entity authority by consistently producing thorough content connecting related topics, signaling expertise. Google prioritizes content from credible sources with documented knowledge. Websites enhance E-E-A-T with author profiles, case studies, references to sources, research, industry reports, and professional documentation. Websites document professional credentials, educational background, and industry experience for key personnel.
3. Create Topic Clusters
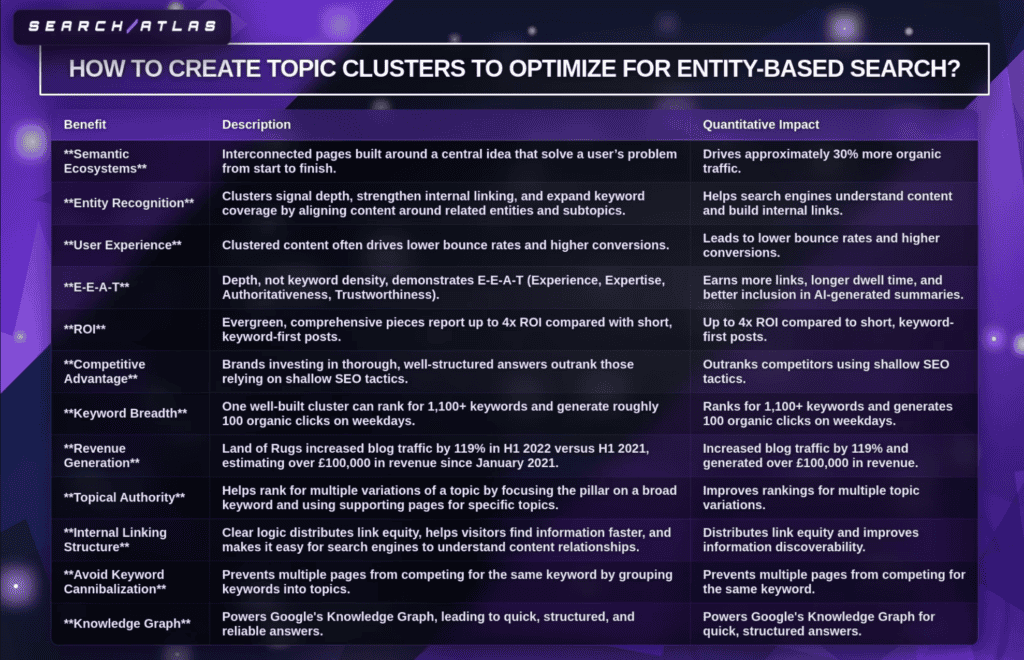
Topic clusters are interconnected content pages built around a central idea that collectively solve a user’s problem from start to finish. Topic clusters drive approximately 30% more organic traffic and hold rankings 2.5 times longer, according to HireGrowth’s 2025 analysis. One well-built topic cluster ranks for 1,100+ keywords and generates roughly 100 organic clicks on weekdays.
How do topic clusters benefit entity-based search? Topic clusters benefit entity-based search by creating semantic ecosystems, strengthening entity recognition, and improving user experience. Topic clusters signal content depth, expand keyword coverage, and align content around related entities and subtopics. Salesforce’s CRM cluster uses entities across pages to allow search engines to understand content. Land of Rugs increased blog traffic by 119% in H1 2022 versus H1 2021, generating over £100,000 in revenue since January 2021 through topic clusters. Evergreen, comprehensive pieces report up to 4x ROI compared with short, keyword-first posts.
What are the core components of a topic cluster? There are five core components of a topic cluster. These are listed below.
- Pillar pages define the main entity and user intent, covering fundamentals and overall strategies through a long-form guide targeting a broad keyword (email marketing).
- Cluster pages explore closely related subtopics in depth (email segmentation strategies), each targeting a specific search intent.
- Internal linking uses contextual links with descriptive anchor text connecting pillar and cluster pages.
- Entities are real-world concepts referenced in pages, creating semantic relationships.
- Schema markup provides explicit signals about content structure and topic relationships.
What are the content depth requirements for topic clusters? Content depth requirements for topic clusters involve pillar page length, structured content, author credibility signals, and scannable content. Many successful pillar pages are around 2,000 words or more. Schema markup and structured data (Article schema, FAQ schema, HowTo schema) allow search engines to understand content. Author credibility signals involve full author bylines, credentials, revision history, and Organization/Person schema markup, reinforcing E-E-A-T. Scannable content uses clear H2s/H3s, jump links, and visual summaries/TL; DRs.
How are topic clusters built step by step? Topic clusters are built through three main implementation steps. Firstly, content architecture defines the pillar page on a broad subject and identifies spoke pages covering specific subtopics. Secondly, interlinking creates semantic reinforcement between pages. Pillar-to-spoke links go from the pillar page to every spoke page. Spoke-to-pillar links go from every spoke page back to the pillar page. Spoke-to-spoke contextual links connect related spoke pages. Descriptive anchor text clearly describes the target page’s entity. Thirdly, the schema for relationships uses ItemList Schema on pillar pages for spoke pages, FAQPage Schema on spoke pages answering common questions, and hasPart and isPartOf properties to define relationships between content.
What implementation mistakes are avoided when building topic clusters? Implementation mistakes to avoid in topic clusters involve three main categories. Structural failures involve weak internal linking and shallow/fragmented clusters. Content quality issues involve a lack of E-E-A-T (generic overviews underperforming content with named practitioners) and AI use without genuine expertise. Maintenance oversights involve content decay, stale pillars, a lack of audits, and failure of content pruning.
How are topic cluster success and optimization measured? Topic cluster success and optimization are measured through six key metrics. Entity Visibility/Relevance shows how clearly Google understands a brand’s connection to key entities. Keyword Breadth per Cluster measures the unique queries and intents a cluster ranks for. Organic Search Visibility (Share of Voice) measures the share of impressions and rankings relative to competitors. Engagement Depth tracks scroll depth, time on page, and internal link CTR. Answer Inclusion Rate measures the percentage of monitored keywords earning a citation in AI Overviews (approximately 20% of searches). Conversion Lift from Organic measures increases in conversions tied to SEO traffic.
4. Implement Internal Linking
Internal linking connects meaning, not just pages, allowing users to explore complete topics and search engines to gain a clear sense of content relationships. Internal links allow search engines to find, index, and understand pages, acting as a roadmap for Google. Generative AI crawlers rely on context to understand relationships between expertise and content. Internal links act as a ranking factor, confirmed by Google.
What are the key strategies for entity-based internal linking? There are four key strategies for entity-based internal linking. These are listed below.
- Establish website hierarchy signals core pages through layered linking (homepage to category to product pages).
- Build content hubs and topic clusters through a broad pillar page targeting a main keyword, supported by cluster pages exploring related subtopics.
- Use keyword-focused anchor text that tells Google what the linked page is about (“best coffee machines,” “best espresso machine”).
- Add contextual links showing Google and users the relationship between topically related articles.
How does internal entity linking build a Content Knowledge Graph? Internal entity linking builds a Content Knowledge Graph by linking every mention of a specific entity (“dental implants”) back to its authoritative service page. Every mention of a location (“Chicago”) links to its dedicated location page. Businesses with multiple locations or service lines benefit from full internal entity architecture across all page types. The sweet spot for internal links to each page is 10-20; after 20, diminishing returns are observed.
What are the benefits of internal linking for entity-based search? The benefits of internal linking for entity-based search involve enhanced crawlability, improved user engagement, and distribution of link equity. A strong internal linking structure is a powerful SEO strategy, as pages without internal links are not discovered by Google. Internal linking sprints lead to a 10-20% growth in content cohorts within weeks. Internal linking improves user engagement by connecting related pages, reducing bounce rates, and encouraging longer exploration. Internal linking distributes link equity (SEO value or authority) between pages.
What are common internal linking mistakes to avoid? Common internal linking mistakes to avoid involve over-optimizing anchor text, ignoring user experience, and neglecting regular audits. Stuffing anchor texts with keywords backfires; anchor texts stay natural and relevant. Too few links result in missed opportunities; too many links overwhelm users and dilute link value. Each link has a clear purpose, guiding users to content that enriches their understanding. Google starts ignoring internal links once the same anchor text is found 200 times on the same domain.
5. Get External Corroboration
External corroboration ensures AI systems recognize a brand as a real, trusted entity, preventing search engines from ignoring websites due to a lack of structured proof. External corroboration provides proof of a business’s reality, transforming the business from text into a verified fact. AI engines use triangulation to verify business data by cross-referencing information across multiple independent sources, assigning a high Confidence Score when sources align.
What categories of data do AI systems use for verification? AI systems use three primary categories of data for verification. Official and authoritative sources include government websites, business registries, tax records, and industry-specific organizations. Google Business Profile acts as a cornerstone for local businesses. Publicly available real-time data encompasses news APIs, social media platforms, and online directories. Proprietary and internal business data (CRM systems, sales analytics) provide structured data feeds.
How do canonical identifiers and public Knowledge Graph integration enhance AI recognition? Canonical identifiers and public Knowledge Graph integration enhance AI recognition by providing stable IDs resolvable by AI engines (Wikidata Q-IDs, Google Knowledge Graph MIDs, well-formed schema @id on owned pages). The sameAs property in the Organization schema explicitly links a brand to authoritative external sources (Wikipedia, LinkedIn company pages, Crunchbase profiles). Without sameAs links, AI engines cannot definitively identify the entity. Google AI Overviews and Gemini retrieval paths heavily rely on Google’s Knowledge Graph, making entities without a canonical ID invisible.
How does securing brand presence on AI “seed” sites improve AI verification? Securing brand presence on AI “seed” sites improves AI verification because seed sites are trusted databases that AI models use for training. Wikidata is most critical for verification, directly feeding Google’s Knowledge Graph. Wikidata requires proof of “notability” for listing. Crunchbase acts as a standard for business data, startups, funding, and company types. AI uses Crunchbase to verify activity and leadership. The Better Business Bureau (BBB) represents a gold standard for local businesses in North America, signaling Trustworthiness (E-E-A-T). An essential checklist of trusted seed sites involves Google Business Profile, Apple Maps, Bing Places, Yelp, Facebook, LinkedIn, Twitter, Instagram, YouTube, Pinterest, Foursquare, Data Axle, Yellow Pages, Dun & Bradstreet, Glassdoor, Wikipedia, Wikidata, Crunchbase, and BBB.
Why is N-A-P consistency critical for AI trust and ranking? N-A-P (Name, Address, Phone number) consistency is critical for AI trust and ranking because AI models are strict; small changes (“St.” versus “Street”) lower AI trust. Inconsistency leads AI to treat conflicting data as separate entities, splitting ranking strength, authority, and reviews. Businesses establish a Master Record for N-A-P. Businesses audit the “Big Four” directories: Google Business Profile, Bing Places, Apple Maps, and Facebook. Small errors (20% of citations having the wrong number) reduce AI’s probability score (80% confidence), leading to lower rankings.
How do fact density and inline citations impact generative AI visibility? Fact density and inline citations impact generative AI visibility significantly, with the Princeton GEO paper finding that adding statistics, quotations, and citations to a page improved visibility in generative engines by up to 40%. AI engines retrieve specific, dated, and sourced facts, filtering out vague claims. A sentence “AI-referred sessions jumped 527% between January and May 2025 (Previsible 2025 AI Traffic Report)” is highly citable. Conducting studies that benefit the industry provides a method to get referenced by authoritative sites.
Why is freshness and corroboration important for AI citation rates? Freshness and corroboration are important for AI citation rates because AI engines favor recent content aligning with other authoritative sources. Perplexity data shows content older than 12 months sees a 37% citation rate, compared to 82% for content updated within the last 30 days. Rank.bot Research indicates content updated within 30 days earns approximately 3x more AI citations than older content across Perplexity, ChatGPT, and Google AI Overviews. Sites refreshing content every two weeks capture 4-10x more AI citations than sites refreshing annually. A “60-day freshness loop” involves a schema timestamp refresh plus an updated directory profile and third-party mention.
What platform-specific corroboration tactics optimize for different AI models? Platform-specific corroboration tactics optimize for different AI models, as each model has unique data preferences. ChatGPT leans on Bing’s live index and its own training data, favoring entities consistently appearing in high-weight training sources (Wikipedia, major publications, Reddit, Stack Overflow). For ChatGPT, businesses prioritize Wikipedia or Wikidata presence, build citations across authoritative third-party sources, and ensure strong Bing indexation. Claude relies on training data with a known cutoff, requiring the entity to be cleanly defined within that training window across multiple corroborating sources. For Claude, businesses prioritize presence on high-authority domains and consistent entity descriptions.
What Signals Influence Entity-Based Rankings?
Entities are distinct, well-defined concepts functioning as semantic primitives, context stabilizers, and relationship frameworks within AI systems. Entities represent “nodes of information” in AI’s view (persons, places, organizations, products, abstract ideas). Google’s search systems, particularly since 2025, rank entities, not just keywords, with the Knowledge Graph serving as a central component for SEO.
The 10 main signals are influencing entity-based rankings. These are listed below.
- Proximity and Relevance measure volume and quality of mentions, links, and content associating a brand with a core topic. High volume of mentions from relevant sources increases entity relevance by 30-50%.
- Brand Identity uses structured data, verified social profiles, and consistent citations. A well-optimized brand entity acts as an anchor for 70% of related content.
- Topical Authority builds comprehensive content clusters (pillar pages supported by detailed articles on sub-entities), improving topical completeness scores by 20-40%.
- Internal Connectivity creates logical, hierarchical website architecture with distinct silos for entities/topics, passing 10-15% of link equity through PageRank computation.
- External Connectivity involves backlinks from authoritative, topically relevant websites, contributing 20-30% to authority through relevance and PageRank.
- Author Expertise evaluates the expertise and history of individuals producing content. Content from recognized experts sees a 15-25% boost in perceived authority.
- Semantic Richness maps related concepts and integrates sub-topics. Comprehensive content covering 80% of related concepts improves user intent alignment by 20%.
- Local Optimization maintains a consistent association with target locations through localized content and directories. Consistent NAP data across 50+ local directories improves local pack rankings by 10-20%.
- Structured Data (Organization, Product, LocalBusiness, FAQPage) explicitly defines relationships, improving interpretation accuracy by 10-15%.
- Knowledge Graph Claiming secures a Wikipedia page and consistent listings across GMB, Crunchbase, LinkedIn, and Wikidata, increasing branded search volume by 5-10%.
How do entities influence Google’s ranking systems technically? Entities influence Google’s ranking systems technically by acting as interpretation mechanisms in semantic retrieval and matching processes, not as standalone ranking factors. Entities are used as embeddings (numerical vector representations) to measure semantic similarity and intent. Google’s systems (retrieval systems, quality classifiers, re-ranking layers) consume entity-derived features, indirectly influencing ranking outcomes.
What are the directly related attributes and signals from Google’s API? Directly related attributes and signals from Google’s API involve seven main features. EntityAnnotations represent extracted and disambiguated entities attached to documents. topicEmbeddingsVersionedData provides vector representations for topical similarity and clustering. site2vecEmbeddingEncoded offers site-level embeddings summarizing topical focus. siteFocusScore and siteRadius measure site-wide topical coherence. contentEffort and OriginalContentScore signal originality and depth, used in quality evaluations.
Where do entities operate within Google’s search pipeline? Entities primarily operate early in Google’s search pipeline, specifically in Step 2 (Entity recognition and clarification), Step 3 (Retrieval and candidate generation), and Step 4 (Topic and intent classification). Entities do not act as independent ordering signals. Entity-generated features are consumed by systems that affect ranking (Q*, Helpful Content, Twiddlers).
Does sentiment act as a ranking signal for entities? Sentiment acts as a ranking signal for entities, particularly for local businesses and places, as described in US Patent 9,317,559 (granted April 19, 2016). Google’s help pages for places list sentiment scores, generated from review text, as a primary component in generating ranking scores for entities. The sentiment-specific ranking process involves three steps. Firstly, the identification of text providing reviews of entities. Secondly, the assignment of sentiment scores to that review text. Thirdly, generation of ranking scores for entities, based at least in part on sentiment scores.
What are Google’s core local ranking factors intersecting with entity recognition? Google’s core local ranking factors intersecting with entity recognition involve three main elements. Relevance measures how well business information matches search queries. Distance assesses the proximity between the searcher and the business location. Prominence reflects overall authority derived from reviews, links, mentions, articles, and directories.
Common Misconceptions About Entity-Based Search
Entity-based SEO is an evolution of traditional SEO that integrates with keyword optimization, prioritizing semantic understanding over pattern matching. Entity-based SEO recognizes “MBA programs” as an entity type with attributes and relationships, not merely a phrase. Entity-based SEO is not a replacement for traditional SEO; keywords still matter for search demand signals, backlinks for authority, and technical SEO remains essential.
What are the main misconceptions? There are nine main misconceptions about entity-based search. These are listed below.
- Entity-based SEO replaces traditional SEO. Entity-based SEO integrates with keyword optimization rather than replacing it. Keywords still matter for search demand signals.
- A numeric entity authority score exists. No numeric entity authority score exists within Google’s systems. Search engines comprehend concepts and their relationships.
- Entity clarity matches keyword rankings. Entity clarity beats keyword rankings. BrightEdge research shows 83.3% of AI Overview citations come from pages beyond the traditional top 10 organic results.
- Schema is a shortcut. Treating schema as a shortcut without substantive content fails. Schema requires substantive content backing.
- Thin entity pages rank. Publishing thin, weak entity pages that lack depth and authority fails. Comprehensive content matters.
- Chasing unrelated entities works. Chasing unrelated entities dilutes relevance and confuses search engines.
- Internal linking is optional. Ignoring internal linking and content structure prevents Google from mapping relationships.
- Mixed terminology is acceptable. Sending inconsistent signals through mixed terminology, shifting positioning, or conflicting descriptions hinders entity understanding.
- The Knowledge Graph ranks pages directly. The Knowledge Graph itself does not rank pages; the Knowledge Graph supports entity disambiguation, factual validation, and relationship analysis.
How does entity-based SEO differ from traditional keyword SEO? Entity-based SEO differs from traditional keyword SEO by prioritizing semantic understanding, where AI systems recognize concepts (entities) and their relationships, rather than just matching keywords. Traditional keyword SEO focuses on pattern matching and ranking pages based on backlinks, domain authority, and content quality for specific phrases. Entity-based SEO is highly future-proof, critical for ranking for AI-driven search features and SERP features (Knowledge Panels). Traditional SEO has low future-proofing, struggling to adapt to algorithm changes.
What is the role of entities in search engine ranking? Entities in search engine ranking function as interpretation mechanisms participating in semantic retrieval and matching processes. Google does not assign an explicit “entity score,” nor are there universal entity density thresholds guaranteeing rankings. Entity coverage supports quality and originality evaluation, but does not provide direct ranking boosts in isolation. Google does not reward “entity completeness” as a standalone ranking factor. Schema markup improves content parsing by Google’s systems but does not directly influence scoring.
What is the impact and measurement of entity-based SEO? The impact of entity-based SEO involves influencing rich snippets, organic results, and letting websites maintain adaptability against algorithm updates. Entity-based SEO targets a broad range of SERP features (featured snippets, knowledge panels, People Also Ask) by focusing on context-rich content and using schema markup. Entity-optimized content is 50% more likely to appear in featured snippets. Success is measured by tracking Knowledge Panel appearances, rich snippet frequency, and entity performance based on traffic from entity-based searches. Tools available for measurement involve Google Search Console, schema validation, Google’s Rich Results Test tool, and entity trackers (Techsalerator).
How do brand mentions and authority signals influence AI models? Brand mentions and authority signals influence AI models because AI models favor content recognized across the web, with citations or mentions on reputable sites, forums, or blogs. Building brand presence on third-party platforms LLMs heavily trust (Reddit, Wikipedia, Google Reviews) is crucial for authority and citation. Mentions, backlinks, and discussions around content increase the chances of content being referenced. AI systems pull information from sources that appear credible and widely referenced. Sentiment matters; negative sentiment in forums and reviews influences how AI frames a brand. Earning quality backlinks from authoritative sites signals content trustworthiness. A health article benefits from backlinks from credible health organizations, government sites, or respected medical publications.
What is the impact of AI on search and entity optimization? The impact of AI on search and entity optimization is significant, with 79% of prospective students reading AI-generated overviews in search results and 37% specifically using ChatGPT to research colleges and universities. Only 30% of institutions have a formal strategy for AI search, and over 50% of institutions lack established SEO plans altogether. BrightEdge research shows 83.3% of AI Overview citations come from pages beyond the traditional top 10 organic results, indicating entity clarity beats keyword rankings. Fractl research indicates 66% of consumers believe AI will replace traditional search within five years, and 82% find AI search more helpful than traditional SERPs.
How can Wikipedia be used for entity-focused SEO? Wikipedia is used for entity-focused SEO because Wikipedia is a semi-structured knowledge base heavily used by Google for entity understanding. Key elements to analyze on a Wikipedia page involve the table of contents (which demonstrates solid topic coverage) and the first sentence (which provides brief, clear information, synonyms, and disambiguation). Internal links use anchor text to signal ranking pages and demonstrate connections to semantically close subjects. The “See also” section exemplifies content designed for topic coverage. The references section acts as an external validator for trusted sources. Wikipedia content is not copied directly; Wikipedia is used for contextual understanding. Identifying entity variants from Wikipedia involves searching for the main entity, where bolded text represents related entity variants (“roof repair” and “roof inspection” for “roof maintenance”).
How Entity-Based Search Shapes the Future of SEO and AI Search?
Entity-based search shapes the future of SEO and AI search by establishing a new discipline focused on relevance engineering and interconnected semantic structures to maximize inclusion in AI-generated answers across platforms (ChatGPT, Perplexity, Google’s AI Overviews). This optimization shifts search from keyword-based “Strings” to understanding distinct “Things” using knowledge graphs, and now to AI-driven “Systems” operating on structured entity ecosystems. The search engine is becoming a reasoning engine, prioritizing “context-first, not word-first answers” through AI algorithms (BERT, MUM, RankBrain, Gemini).
How has search evolved with AI integration? Search has evolved from keyword-based “Strings” to understanding distinct “Things” using knowledge graphs, and now to AI-driven “Systems” operating on structured entity ecosystems. This evolution transforms the search engine into a reasoning engine, moving beyond exact words to prioritize entity patterns. Google’s Knowledge Graph, containing over 8 billion entities and 800 billion facts, drives this shift. Technologies (RankBrain (2015), BERT (2019), MUM, Gemini algorithms) prioritize entity patterns over exact word matches.
What is the new digital visibility unit in AI search? The new digital visibility unit in AI search is the entity, a well-defined, machine-readable representation that has replaced the webpage as the most powerful atomic unit. Entities are “a thing or concept that is singular, unique, well-defined, and distinguishable” (“Malcolm Gladwell,” “Paris,” “iPhone 15”). Entities reduce ambiguity (distinguishing “Apple Inc.” from the fruit) and carry built-in relationships, allowing ranking for related searches without explicit keyword targeting.
What is the ROI of implementing an advanced schema? The ROI of implementing an advanced schema involves three main outcomes. Advanced schema produces a 300% potential improvement in LLM response accuracy with enterprise Content Knowledge Graphs (CKGs). Sites deploying deeply nested, error-free advanced schema observe a 20-40% traffic lift. Structured data acts as the direct communication layer between brands and AI systems. Google reinforced at Search Central Live Dubai on October 20, 2025, that structured data is foundational for AI comprehension.
What architectural solutions support entity-based SEO? Architectural solutions supporting entity-based SEO involve Content Knowledge Graphs (CKGs) and deep Schema.org markup. A CKG is an interconnected network of entities built in Schema.org vocabularies and expressed in JSON-LD, mapping entities hierarchically (Organization → Brand → Product → Offer → Review). Basic, fragmented schema creates “isolated data islands” that force AI into expensive inference loops. Schema markup is the direct communication layer between brands and AI systems.
What critical properties build trust and authority for entities? Critical properties building trust and authority for entities involve @id and sameAs. The @id property creates a consistent identifier connecting related entities across a website. The sameAs property links entities to authoritative external references (Wikipedia, Wikidata, LinkedIn, Google Knowledge Graph). This linking acts as an authority transfer mechanism, significantly increasing the likelihood of citation by AI models.
What are the new KPIs for Generative AI visibility? The new KPIs for Generative AI visibility involve five main metrics. Share of Model (SOM) measures the percentage of time a brand or entity appears in generative responses for specific category queries, replacing “share of voice.” AI Visibility Score tracks brand presence across AI platforms. Citation Likelihood increases when trusted third-party entity graphs validate facts. Brand Accuracy measures the delta between declared schema and AI-generated descriptions. Grounding Quality measures the 1:1 match between schema and AI representation, preventing entity drift.
What are the threats to entity visibility in AI search? The threats to entity visibility in AI search involve entity drift and schema drift. Entity drift occurs when inconsistencies exist between a website and its Google Business Profile, or when human-visible content changes but machine-readable schema remains static, lowering AI confidence scores. Schema drift, the greatest threat to visibility at enterprise scale, occurs when the schema becomes outdated. A governance mandate defeats schema drift by assigning clear accountability for canonical entity definitions, ensuring template-level integration where schema updates automatically with CMS content changes.
Do Entities Improve Rankings?
Yes, entities improve rankings indirectly by acting as interpretation mechanisms for semantic retrieval and matching within Google’s ranking systems. Entities operate early in the search pipeline, specifically in Step 2 (entity recognition) and Step 3 (retrieval), with their outputs persisting downstream to generate features consumed by ranking systems. Google’s initial ranking for new content, particularly post-Helpful Content Update, is significantly influenced by the density of related entities within the text. A 432-word page ranks highly with nearly double the related entity density of competitors.
How do entities affect rankings without acting as standalone factors? Entities are not standalone ranking factors and do not directly boost rankings. Entities enable content to be understood, classified, and trusted by Google’s AI-driven search systems. Entity understanding fails with ambiguous names or conflicting dominant entities, potentially routing pages into incorrect classifiers and impacting eligibility. Entity density provides initial ranking advantages, as seen in a test where a page reached #1 within 24 hours due to entity density. Sustained high rankings depend on a positive user experience. Negative user interactions (100% bounce rate, 13-second time on page) lead to ranking drops of approximately 15 positions.
Is Entity-Based Search the Same as Semantic Search?
Yes, entity-based search functions as a core component of semantic search, with Google operating as a semantic search engine since the 2013 introduction of the Hummingbird algorithm. Hummingbird affected over 90% of all searches, enabling Google to immediately involve entities from its Knowledge Graph for query processing and ranking. Google’s evolution into a fully semantic system traces back to 1999. All major Google innovations (RankBrain, E-A-T, BERT, MUM) directly or indirectly support Google’s goal of becoming a fully semantic search engine.
What are the limitations of purely entity-based search approaches? Purely entity-based search approaches (PESS4IR) currently have limited applicability. Existing entity linking tools (DBpedia Spotlight, REL) only completely annotate a small percentage of queries. DBpedia Spotlight annotates 72% of 250 Robust04 queries; REL annotates 6.8%. PESS4IR outperforms traditional models (Galago) for highly represented queries with high annotation scores (nDCG@5 of 1.000 for queries with ≥ 0.75 annotation score). PESS4IR is generally outperformed by state-of-the-art models (LongP) for broader query sets.











