

Although a more technical part of SEO optimization, robots.txt files are a great way to improve the crawling and indexing of your website.
This article will break down all of the details related to robots.txt and highlight common issues related to its implementation.
If you run a seo audit in the Search Atlas site auditor, you may see issues flagged related to your robots.txt file. You can use this article to troubleshoot and resolve those issues.
What are robots.txt Files?
The robots.txt file tells web crawlers which areas of your website they are allowed to access and which areas they are not allowed to access. It contains a list of user-agent strings (the name of the bot), the robots directive, and the paths (URLs) to which the robot is denied access.
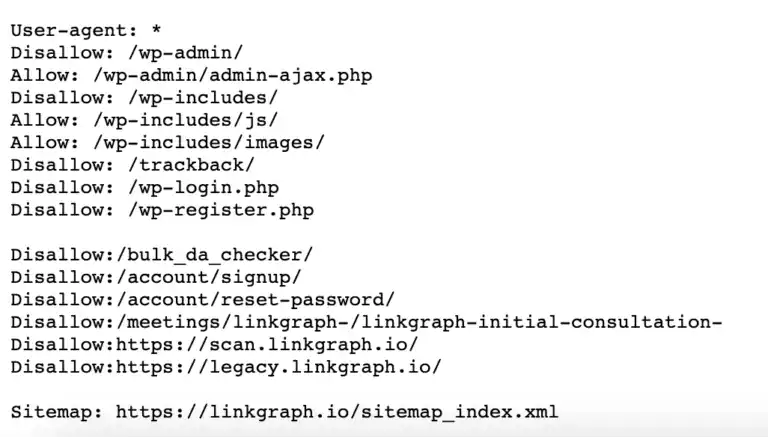
When you create a website, you may want to restrict access to certain areas pages of your search engine crawlers and prevent specific pages from being indexed. Your Robots.txt file is where web crawlers will understand where they do and do not have access.
Robots.txt is a good way to protect your site’s privacy or to prevent search engines from indexing content that is not rank-worthy or ready for public consumption.
Also, if you don’t want your website to be accessed by other common web crawlers like Applebot, Ahrefbots, or others, you can prevent them from crawling your pages via your robots.txt file.
Where is my robots.txt File Located?
Robots.txt file is a text file that is placed in the root directory of a website. If you don’t yet have a robots.txt file, you will need to upload it to your site.
If the web crawler cannot find the robots.txt file at the root directory of your website, it will assume there is no file and proceed with crawling all of your web pages that are accessible via links.
How you upload the file will depend on your website and server architecture. You may need to get in contact with your hosting provider to do so.
Why Should I Care About robots.txt?
The robots.txt file is considered a fundamental part of technical SEO best practice.
Why? Because search engines discover and understand our websites entirely through their crawlers. The robots.txt file is the best way to communicate to those crawlers directly.
Some of the primary benefits of robots.txt are the following:
- Improved crawling efficiency
- Prevent less valuable pages from getting indexed (e.g. Thank you pages, confirmation pages, etc.)
- Prevents duplicate content and any penalties as a result
- Keeps content away from searchers that is not necessarily of high-value
How Does robots.txt Work?
When a search engine robot encounters a robots.txt file, it will read the file and obey the instructions.
For example, if Googlebot comes across the following in a robots.txt:
User-agent: googlebot
Disallow: /confirmation-page/
It also won’t be able to access the page to crawl and index. It also won’t be able to access any other of the pages in that subdirectory, including:
- /confirmation-page/meeting/
- /confirmation-page/order/
- /confirmation-page/demo/
If a URL is not specified in the robots.txt file, then the robot is free to crawl the page as it normally would.
Best Practices for robots.txt
Here are the most important things to keep in mind when implementing robots.txt:
- robots.txt is a text file, so it must be encoded in UTF-8 format
- robots.txt is case sensitive, and the file must be named “robots.txt”
- The robots.txt file must be placed at the root directory of your website
- It’s best practice to only have one robots.txt available on your (sub)domain
- You can only have one group of directives per user agent
- Be as specific as possible as to avoid accidentally blocking access to entire areas of your website, for example, blocking an entire subdirectory rather than just a specific page located within that subdirectory
- Don’t use the noindex directive in your robots.txt
- robots.txt is publicly available, so make sure your file doesn’t reveal to curious or malicious users the parts of your website that are confidential
- robots.txt is not a substitute for properly configuring robots tags on each individual web page
Common Issues Related to robots.txt
When it comes to website crawlers, there are some common issues that arise when a site’s robots.txt file is not configured properly.
Here are some of the most common ones that occur and will be flagged by your Search Atlas site audit report if they are present on your website.
1. robots.txt not present
This issue will be flagged if you do not have a robots.txt file or if it is not located in the correct place.
To resolve this issue, you will simply need to create a robots.txt and then add it to the root directory of your website.
2. robots.txt is present on a non-canonical domain variant
To follow robots.txt best practice, you should only have one robotxt.txt file for the (sub)domain where the file is hosted.
If you have a robots.txt located on a (sub)domain that is not the canonical variant, it will be flagged in the site auditor.
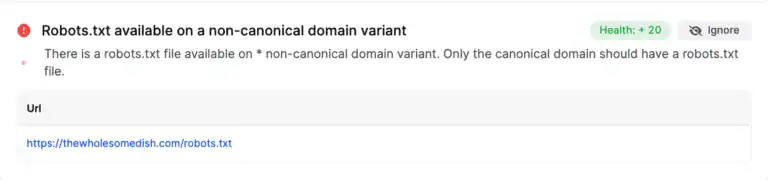
Non-canonical domain variants are those pages that are considered duplicate pages, or copies of master pages on your website. If your canonical tags are properly formatted, only the master version of the page will be considered the canonical domain, and that is the version of the page where your file should be located.
For example, let’s say your canonical variant is
- https://www.website.com/
Your robots file should be located at:
- https://www.website.com/robots.txt
In contrast, it should not be located at:
- https://website.com/robots.txt
- http://website.com/robots.txt
To resolve this issue, you will want to update the location of your robots.txt. Or, you’ll need to 301 redirect the other non-canonical variants of the robots.txt to the actual canonical version.
3. Invalid directives or syntax included in robots.txt
Including invalid robots directives or syntax can cause crawlers to still access the pages you don’t want them to access.
If the site auditor identifies invalid directives in your robots.txt, it will show you a list of the specific directives that contain the errors.
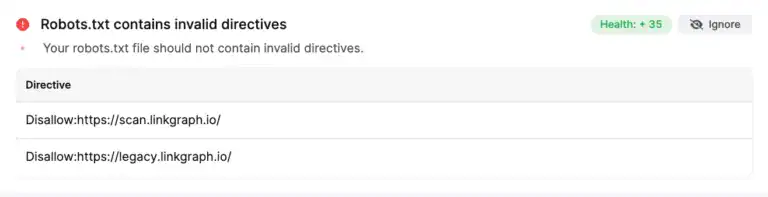
Resolving this issue involves editing your robots.txt to include the proper directives and the proper formatting.
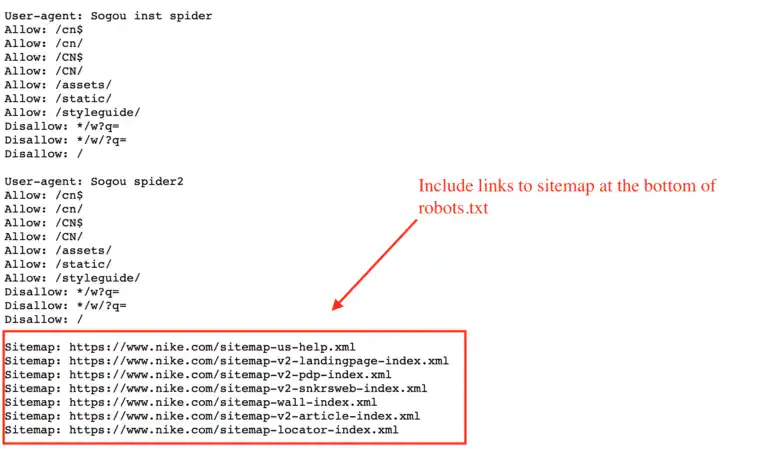
4. robots.txt should reference an accessible sitemap
It is considered best practice to reference your XML sitemap at the bottom of your robots.txt file. This helps search engine bots easily locate your sitemap.
If your XML sitemap is not referenced in your robots file, it will be flagged with the following message in the Site Auditor.

To resolve the issue, add a reference to your sitemap at the bottom of your txt file.
5. robots.txt should not include a crawl directive
The crawl-delay directive instructs some search engines to slow down their crawling, which causes new content and content updates to be picked up later.
This is undesired, as you want search engines to pick up on changes to your website as quickly as possible.
For this reason, the Search Atlas site auditor will flag a robots.txt file that includes a crawl directive.

Conclusion
A properly configured robots.txt file can be very impactful for your SEO. However, the opposite is also true. Do robots.txt incorrectly, and you can create huge problems for your SEO performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}